Programação Reativa - Parte 4: Sistemas reativos
Publicado em:
@ljtfreitas
Nos três posts anteriores, vimos os fundamentos principais da programação reativa, incluindo muitos exemplos de código, processamento concorrente e contrapressão. Que lindo! Mas serão esses conceitos aplicáveis para aplicações de grande porte e sistemas inteiros? Esse post irá explorar os detalhes de uma verdadeira aplicação reativa.
Caso você não tenha lido os posts anteriores, uma recapitulação:
- O que é programação reativa?
- Exemplos de código com o RxJava
- Processamento concorrente, paralelismo e backpressure
Por que queremos um sistema “reativo”?
“Somos o que repetidamente fazemos. (Aristóteles)”
Até aqui, estudamos os fundamentos do modelo de programação reativo. Mas um modelo de programação se aplica a um código, que por sua vez constrói um software. Eventualmente, um ou mais softwares podem construir um sistema. Faria sentido, então, que nossos sistemas fossem reativos?
Os requisitos e as necessidades do software, nos últimos anos, mudaram drasticamente. Há poucos anos atrás, lidávamos com quantidades muito menores de dados, aplicações gigantescas rodavam em dezenas de servidores enormes com tempos de resposta muito superiores aos atuais, e janelas de manutenção demoravam horas para serem realizadas.
Hoje, temos programas rodando em todos os lugares: em casas, carros, e dezenas de outros dispositivos; estamos conectados o tempo todo, usando aplicações web e aplicativos; temos computação em nuvem, e o hardware se tornou praticamente uma commodity, tornando quase trivial a criação de clusters com dezenas de aplicações; os dados gerados são mensurados em petabytes. Naturalmente, os usuários se tornaram mais exigentes: querem respostas 100% do tempo, o tempo todo, o mais rapidamente possível!
Esse conjunto de necessidades (entre outras) fez emergir uma abordagem diferente para arquitetura de sistemas. Uma abordagem para construção de softwares mais escaláveis, desacoplados e flexíveis; mais tolerantes a (inevitáveis) falhas, tratando-as de maneira adequada; mais fáceis de se evoluir e manter.
Essa abordagem recebeu o nome de “sistemas reativos”. Mas o que é um sistema reativo de fato?
O que é um sistema “reativo”?
Como tudo o mais em software, provavelmente a resposta para a pergunta acima seria “depende” :). Brincadeirinha: essa é uma pergunta natural e comum, e imagino que você esteja lendo esse post esperando uma resposta, certo? Seria muita pretensão da minha parte escrever a “definição definitiva” sobre o assunto. Mas outras pessoas já responderam essa questão!
O Manifesto Reativo
Em 2014, algumas empresas e membros da comunidade publicaram o Manifesto Reativo, uma declaração e uma definição a respeito do que são (ou deveriam ser) os tais “sistemas reativos” e quais características eles compartilham.
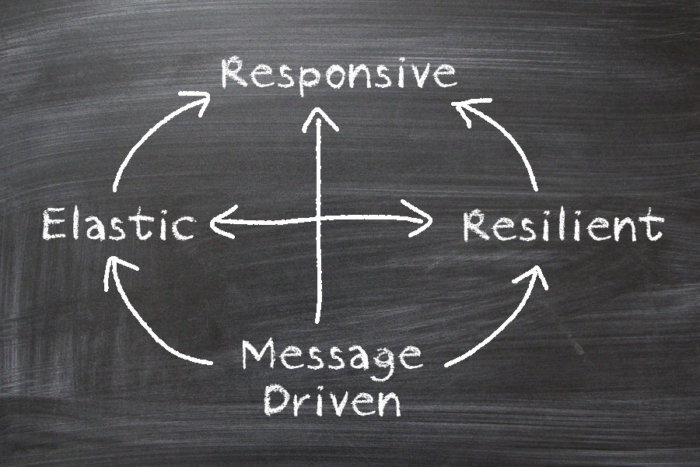
Segundo o Manifesto, os sistemas reativos são baseados em quatro princípios:
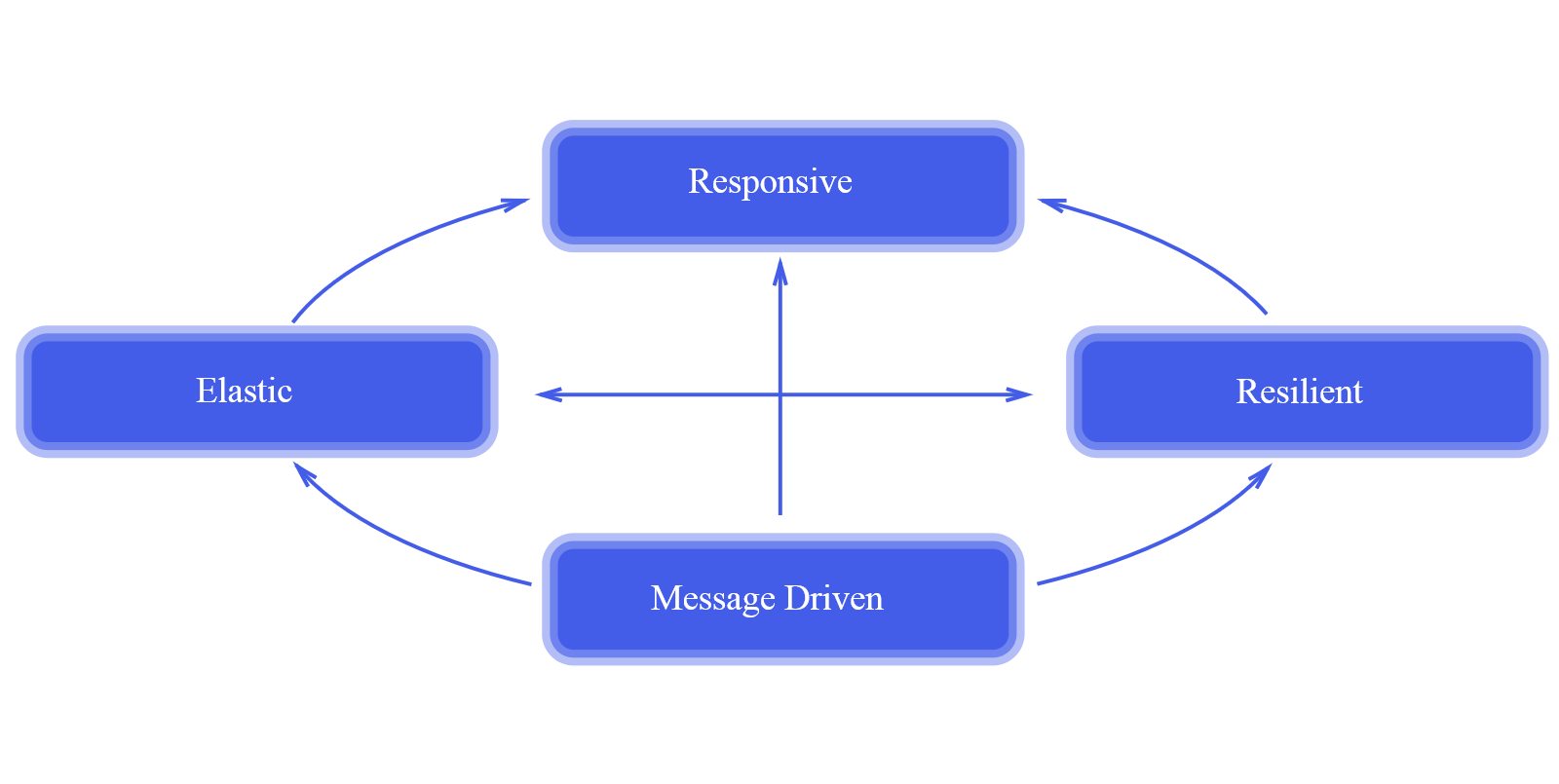
Responsivo
O sistema sempre deve responder em tempo hábil, se possível, mantendo a latência baixa. Problemas devem ser detectados rapidamente e tratados como cidadãos de primeiro nível, com máxima eficiência e elegância.
Resiliente
O sistema deve continuar respondendo em caso de falha (e tenha certeza, as coisas irão falhar). Isso é alcançado com algumas práticas, incluindo o isolamento da falha, de modo que cada componente possa contornar seus próprios problemas sem afetar o conjunto, e alta disponibilidade através de replicação. O tratamento da falha não deve afetar o cliente, e o código do software deve refletir claramente a diferença entre o fluxo “normal” e a recuperação de problemas.
Elástico
O sistema deve continuar responsivo mesmo sob variações de carga, incluindo momentos de pico. O sistema deve reagir a essas mudanças aumentando ou diminuindo recursos, o que implica em arquiteturas sem pontos de gargalos centrais, permitindo a divisão ou replicação de componentes.
Orientado a mensagens
O sistema deve utilizar envio de mensagens assíncronas para comunicação entre os componentes. Isso fornece o estabelecimento de fronteiras e baixo acoplamento. A comunicação através de mensagens deve ser explicitamente representada na arquitetura e no código do software. O conceito principal aqui é que os componentes devem reagir aos acontecimentos do sistema, que idealmente serão representados através de eventos (transmitidos através de mensagens assíncronas).
E o que a programação reativa tem a ver com isso?
O modelo da programação reativa se encaixa perfeitamente nesse contexto. O fato de ser naturalmente um modelo orientado a eventos, de considerar os erros como itens de primeira classe no fluxo, o uso de backpressure para lidar com momentos de pico e controlar o consumo de mensagens, e o fato da construção do código ser declarativa ao invés de imperativa (favorecendo a execução concorrente) fazem da programação reativa a ferramenta ideal para construir esse tipo de aplicação.
Em Java, existem várias opções para a construção de sistemas reativos (naturalmente, usando programação reativa). Um dos frameworks mais famosos da plataforma Java, o Spring foi radicalmente repensado na sua versão mais recente, utilizando o Reactor. Outro framework excelente e bastante conhecido é o Vert.x, que utiliza o RxJava. O Lagom é um framework para construção de microsserviços reativos em Java e/ou Scala, e utiliza extensamente o Akka, entre outros frameworks.
Os frameworks que citei foram projetados para, com efeito, lidar com as necessidades dos softwares modernos: altas cargas de dados, alta concorrência, alta disponibilidade. Mas, além da programação reativa, como exatamente essas arquiteturas têm conseguido isso?
Arquiteturas não-bloqueantes
Naturalmente, arquiteturas reativas não são a panacéia da engenharia de software ou a proverbial “bala de prata”. Existem diversos modelos de construção de sistemas capazes de resolver problemas de escalabilidade e resiliência. Mas aqui, no tocante a sistemas reativos, eu gostaria de me concentrar em um problema específico: a latência, que é um ponto-chave nas questões comentadas acima.
Podemos definir “latência” como o tempo transcorrido entre o início de um evento e o momento em que seus efeitos se tornam perceptíveis. Para que um sistema seja responsivo, a latência deve ser a menor possível na percepção do usuário. Se a nossa intenção é diminuí-la, surge a pergunta: como?
A programação de software clássica (imperativa) é apenas uma sequência de instruções executadas, de modo linear, em uma única thread, e é o modelo que continua sendo implementado na maioria dos programas (e não há nada necessariamente “errado” nisso). Então, uma abordagem muito comum, usada há anos, é a execução do nosso programa em processos concorrentes, em threads diferentes. A ideia aqui é conseguir fazer mais coisas (concorrentes) com mais threads, “ao mesmo tempo”.
Pensemos como exemplo uma aplicação web convencional ou mesmo uma API: para realizar as tarefas requisitadas, o servidor da aplicação gera uma quantidade de threads (normalmente, uma thread por request). Mas essas threads, na maioria dos casos, passam a maior parte do tempo bloqueadas aguardando algo: uma operação de rede, uma leitura do disco, uma requisição a uma base de dados. Operações de I/O, colocando de outro modo.
Existem dois tipos de threads: “software-threads” (gerenciadas pelo sistema operacional, como as threads do servidor do nosso exemplo) e “hardware-threads” (os processos efetivamente concorrentes, executados por diferentes núcleos do processador). Software-threads são boas porque permitem ao sistema operacional realizar muito mais tarefas simultaneamente do que a quantidade de núcleos que o processador possui, além de fornecer uma abstração para a manipulação de threads na escrita de software. Dito isso, para otimização de performance, é recomendada a criação de um pool de software-threads e o não-compartilhamento de dados entre elas.
Dito isso, voltamos ao problema do I/O, que costuma ser o detalhe-chave na questão da latência. Nossa aplicação web/API utiliza “software-threads” e nosso programa bloqueia o segmento no qual o código está sendo executado, de modo que o compartilhamento dos núcleos da CPU entre múltiplas threads é baseado no tempo. Para processar mais requisições, portanto, precisamos de mais threads; e quanto mais threads utilizarmos de maneira bloqueante, mais threads precisaremos! Naturalmente, o sistema operacional é capaz de lidar com essa situação, administrando a pilha de processos e gerenciando a sincronização e a troca de contextos entre threads. Mas isso é feito com maior sacrifício de hardware, tanto a nível de memória (utilizada no gerenciamento das execuções concorrentes), quanto pelo fato de que a capacidade do processador (número de núcleos) não é efetivamente aproveitada.
Ocorre que esse acoplamento entre threads e I/O não é necessário, e as arquiteturas reativas sugerem se aproveitar desse fato com o uso de uma arquitetura não-bloqueante. Os sistemas operacionais há anos suportam I/O em background, um modelo mais conhecido como NIO (“non-blocking I/O”). O próprio Java, com efeito, tem suporte para NIO desde a versão 4!
Nesse modelo, alguns mecanismos especializados do sistema operacional (por exemplo, epoll no caso do Linux) notificam o software a respeito da operação de I/O utilizando eventos. Desse modo, a thread não permanece bloqueada, podendo ser utilizada pelo programa para atender novas solicitações. Isso demonstra uma perfeita sintonia com o modelo reativo, pois os dados não são solicitados pela aplicação, e sim empurrados (pelo sistema operacional) quando estão disponíveis (ou quando determinados eventos ocorrerem).
Essa arquitetura permite reduzir o número de threads, uma vez que os segmentos não são bloqueados. Também utiliza a CPU de maneira mais eficiente, pois o seu poder de processamento não é compartilhado com base no tempo, mas baseado em eventos. Outros benefícios são o aumento de paralelismo da aplicação, redução do consumo de memória e melhor gerenciamento dos picos de carga (eliminando o limite arbitrário de processos simultâneos), além de (reforçando esse aspecto) um uso mais inteligente do poder real da CPU, pois esse modelo melhora o agendamento dos processos (baseados nas prioridades reais da aplicação, e não no tempo) e reduz o custo de sincronização (entre processos concorrentes). Com o uso mais eficiente do hardware, conseguimos a almejada redução de latência.
Essas melhorias permitem concentrar um maior número de requisições em um único servidor, utilizando um número mínimo de threads (o que também tem o efeito positivo de redução de cu$to$). Voltando ao exemplo da nossa aplicação web/API, o volume de requisições suportadas não está mais limitado a um thread pool de tamanho arbitrário, como seria o caso em um servidor de aplicação convencional e baseado em bloqueio de threads (no caso do Java, um exemplo seria o Tomcat).
Naturalmente, essa arquitetura exige uma profunda mudança tanto no nível do modelo de programação (declarativo, ao invés de imperativo) quanto em relação às ferramentas envolvidas na construção do software: servidores de aplicação, drivers de bancos de dados, frameworks: tudo deve funcionar de maneira não-bloqueante. Uma aplicação reativa nunca deve bloquear o segmento em operações de I/O ou que demandem espera por algum recurso (não-bloqueante + bloqueante = bloqueante).
Em síntese, a motivação de uma arquitetura não-bloqueante é efetivamente explorar o potencial e a capacidade do hardware. As arquiteturas tradicionais, baseadas em bloqueios de threads, não conseguem fazer uso de todo o poder disponível das CPUs, simplesmente porque passam boa parte do seu tempo aguardando operações bloqueantes. Uma arquitetura não-bloqueante permite ao software efetivamente utilizar os ciclos de processamento disponíveis de uma maneira mais eficiente.
Por que queremos um sistema “reativo”? (de novo)
“Não adianta voltar para ontem, porque eu era uma pessoa diferente então. (Lewis Carrol)”
No início do post, como uma tentativa de resposta para essa pergunta, coloquei alguns desafios atuais do desenvolvimento de software como motivação: a constante (e sempre crescente) necessidade de escalabilidade e baixa latência. Mas por que acreditamos que o modelo reativo tem se mostrado mais adequado para essas necessidades?
A programação reativa não é nova. Aplicações orientadas a eventos existem basicamente desde que o mouse foi inventado. Mas sistemas reativos vão além do modelo de programação, e têm se mostrado mais eficientes ao lidar com questões como grandes volumes de dados, responsividade em tempo real e tolerância a falhas. Novamente, a programação reativa oferece um “fit” perfeito ao representar os dados como um fluxo, mas os ganhos efetivos dessa arquitetura são os detalhes descritos no Manifesto Reativo: uma arquitetura naturalmente projetada para responsividade, resiliência, elasticidade e comunicação assíncrona.
Conclusão
Nesse post, vimos as motivações e os porquês de uma arquitetura reativa, em especial as arquiteturas de I/O não-bloqueante, e como os princípios dos sistemas reativos (expostos e detalhados no Manifesto Reativo) se propôem a resolver as necessidades de escala dos softwares modernos.
Mas como falar é fácil, no próximo post vamos fazer um pouquinho (muito!) de código demonstrando esses conceitos na construção de uma aplicação do “mundo real”!
Obrigado e até a próxima!