
Programação Reativa - Parte 3: Processamento concorrente, paralelismo e backpressure
Publicado em:
@ljtfreitas
Nos dois posts anteriores sobre Programação Reativa, estudamos os fundamentos desse paradigma e vimos muitos exemplos de código usando o RxJava. Nesse capítulo, vamos nos focar na abstração sobre a execução assícrona e parelela que os frameworks Rx fornecem, e especialmente em um conceito que é um dos pilares do modelo reativo: a contrapressão ou backpressure.
“A dúvida é o princípio da sabedoria. (Aristóteles)”
Processamento assíncrono
Um dos assuntos que mais causam discussão a respeito da programação reativa é questão do processamento assíncrono. Com efeito, as ideias sobre as quais o paradigma reativo é fundamentado favorecem a execução concorrente do código, assim como ocorre nas linguagens funcionais: código declarativo, funções livres de efeitos colaterais, propagação de estado e imutabilidade. Todos os operadores reativos que vimos no post anterior funcionam dessa forma, de modo que qualquer operação poderia ser executada de maneira assíncrona, ou mesmo em paralelo, sem nenhum problema. Mas isso deve ser feito explicitamente; colocando em outras palavras: a não ser que você diga o contrário, todas as operações irão ocorrer em uma única thread, por uma questão de economia de recursos do hardware. O código abaixo demonstra isso.
Observable.create(emitter -> {
emitter.onNext("one");
emitter.onNext("two");
emitter.onComplete();
}).subscribe(
value -> System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId()),
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
/*
output:
Receive one on Thread 1
Receive two on Thread 1
Receive OnCompleted on Thread 1
*/
O código acima demonstra claramente que não há nenhuma outra thread envolvida; todas as coisas aconteceram na thread corrente do programa, e também seria o caso se tivéssemos realizado mais operações sobre o Observable (map, flatMap, etc). E se os eventos fossem emitidos em uma thread diferente? Vejamos o exemplo abaixo, usando um Subject:
BehaviorSubject<Integer> subject = BehaviorSubject.create();
AtomicInteger counter = new AtomicInteger(0); //efeito colateral; apenas para testes! :)
Runnable runnable = () -> {
int count = counter.incrementAndGet();
System.out.println("Emitting value " + count +
" on Thread " + Thread.currentThread().getId()); //thread em que o onNext está sendo emitido
subject.onNext(count);
};
subject.subscribe(value -> System.out.println("Receive " + value +
" on Thread " + Thread.currentThread().getId())); //thread em que o subscribe está sendo executado
System.out.println("Current thread: " + Thread.currentThread().getId()); //thread atual do programa
// inicializa duas novas threads que farão a emissão dos eventos
new Thread(runnable).start();
new Thread(runnable).start();
Thread.sleep(1000);
/*
output:
Current thread: 1
Emitting value 1 on Thread 12
Emitting value 2 on Thread 13
Receive 1 on Thread 12
Receive 2 on Thread 13
*/
Se você executar esse código, talvez a ordem da saída seja ligeiramente diferente. O detalhe importante a ser percebido no exemplo acima é que a emissão dos eventos e o subscribe ocorrem sempre na mesma thread, sincronamente. Esse é o comportamento padrão dos frameworks Rx, e tambem é o caso do RxJava.
Mas e se quisermos publicar e processar eventos em threads diferentes?
(Um pouquinho de) Schedulers
Um dos princípios de design dos frameworks Rx é fornecer uma fundação simples e segura para programação assíncrona e concorrente. O principal objeto que abstrai esses conceitos é o Scheduler. Naturalmente, a implementação depende de detalhes específicos de cada linguagem e, no caso do RxJava, o comportamento é implementado com o Executor Framework, a API padrão de concorrência do Java.
Para criamos uma instância de um Scheduler, podemos utilizar os métodos de fábrica da classe Schedulers:
// Scheduler indicado para tarefas computacionais comuns
Scheduler computation = Schedulers.computation();
// Scheduler indicado para tarefas envolvendo IO
Scheduler io = Schedulers.io();
// Scheduler que criará uma nova thread para cada unidade de trabalho requerida
Scheduler newThread = Schedulers.newThread();
// Scheduler que irá enfileirar as unidades de trabalho, consumindo-as no formato FIFO usando as threads do poll
Scheduler trampoline = Schedulers.trampoline();
// Scheduler que irá executar todas as unidades de trabalho em uma única thread.
// Indicado para trabalhos que requerem computação sequencial
Scheduler single = Schedulers.single();
// Scheduler criado a partir de um Executor do Java fornecido por você.
// O código abaixo cria um ExecutorService usando a classe Executors, da API padrão do Java.
Scheduler customized = Schedulers.from(Executors.newFixedThreadPool(100));
Um dos pontos fortes dos frameworks reativos é fornecer um nível de abstração simples para o processamento assíncrono, que historicamente é uma grande dor de cabeça para os programadores (incluindo especialmente a linguagem Java). Com efeito, trabalhar diretamente com threads não é algo trivial, envolvendo diversos detalhes complicados, que fatalmente serão refletidos em códigos igualmente complicados.
O papel do Scheduler é simplificar essa complexidade, de tal maneira que não precisamos nos preocupar com os detalhes de baixo nível acerca da manipulação de threads, e sim apenas nos concentrarmos nas operações que desejamos realizar com nosso stream, uma vez escolhido o Scheduler mais adequado à tarefa.
Com os métodos acima, podemos criar um Scheduler para diversos casos de uso. Mas e agora, o que fazemos com ele?
subscribeOn e observeOn
Os métodos subscribeOn e observeOn permitem controlar qual será o comportamento, em relação às threads, da emissão e subscrição de eventos. Ambos recebem um Scheduler como argumento.
subscribeOn
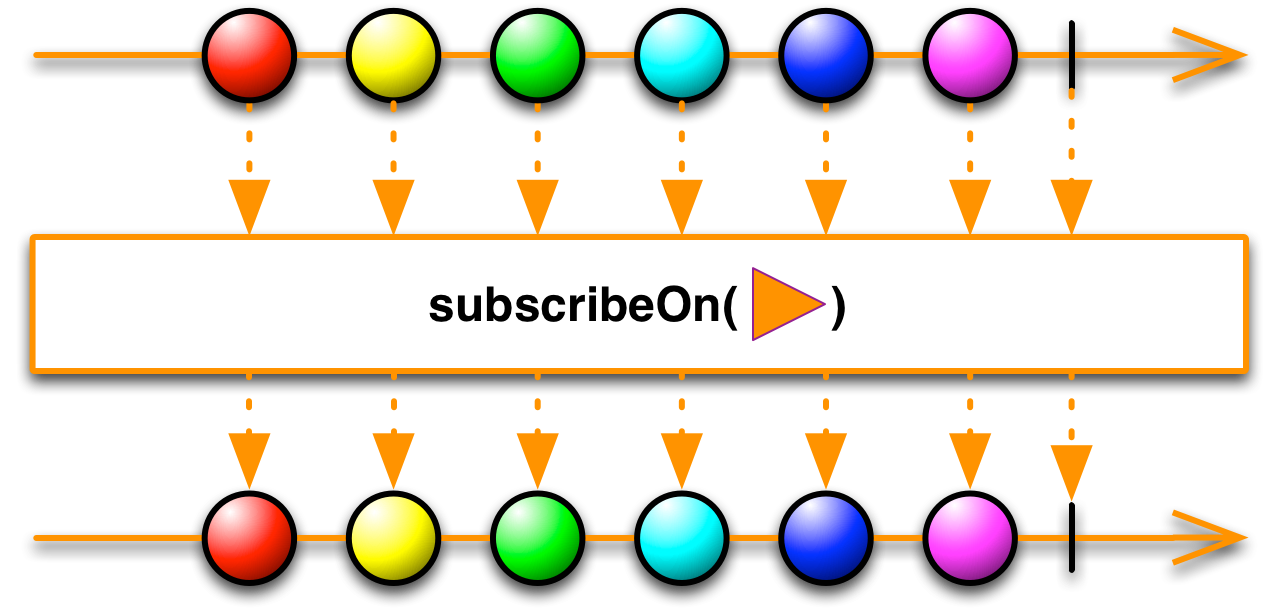
O método subscribeOn permite controlar em qual Scheduler a emissão dos eventos será realizada. Revisitando o exemplo anterior:
Observable.create(emitter -> {
//thread em que o onNext está sendo emitido
System.out.println("Emitting on Thread " + Thread.currentThread().getId());
emitter.onNext("one");
emitter.onNext("two");
emitter.onComplete();
})
.subscribeOn(Schedulers.newThread()) // aqui estamos dizendo o Scheduler em que a emissão de eventos deve ocorrer
.subscribe(
value ->
//thread em que o subscribe está sendo executado
System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId()),
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId()); //thread atual do programa
Thread.sleep(1000);
/*
output:
Current thread: 1
Emitting on Thread 11
Receive one on Thread 11
Receive two on Thread 11
Receive OnCompleted on Thread 11
*/
No exemplo acima, utilizamos o método create (já visto no post anterior) para criação do Observable, mas o comportamento do subscribeOn é o mesmo para qualquer outro método de criação. Vejamos o exemplo abaixo, usando o método de fábrica just:
Observable.just("one", "two")
.subscribeOn(Schedulers.newThread())
.subscribe(
value -> System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId()),
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId());
Thread.sleep(1000);
/*
output:
Current thread: 1
Receive one on Thread 11
Receive two on Thread 11
Receive OnCompleted on Thread 11
*/
Alguns métodos de criação do Observable operam sempre sobre threads diferentes da execução do programa (pois são naturalmente assíncronos); por exemplo, o método interval.
Observable.interval(1000, TimeUnit.MILLISECONDS)
.subscribe(value -> System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId());
Thread.sleep(3000);
/*
output:
Current thread: 1
Receive 0 on Thread 11
Receive 1 on Thread 11
Receive 2 on Thread 11
*/
Usando o subscribeOn em conjunto com esses métodos, também é possível controlar o Scheduler utilizado; outra maneira é usar uma sobrecarga que permite customizar o Scheduler por parâmetro (de maneira consistente, outros métodos como intervalRange também são sobrecarregados da mesma maneira):
Observable.interval(1000, TimeUnit.MILLISECONDS, Schedulers.newThread())
.subscribe(value -> System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId());
Thread.sleep(3000);
/*
output:
Current thread: 1
Receive 0 on Thread 11
Receive 1 on Thread 11
Receive 2 on Thread 11
*/
Em todos os exemplos acima, podemos perceber que os subscribers foram executados na mesma thread em que os eventos foram publicados. Também podemos customizar esse comportamento usando o observeOn.
observeOn
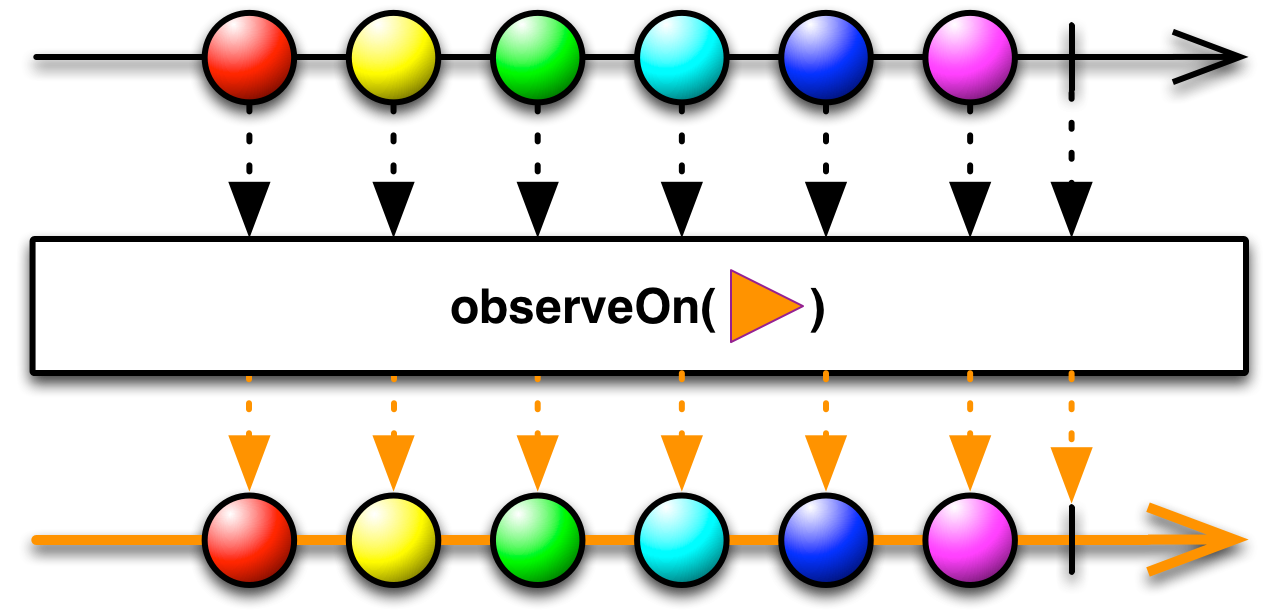
O método observeOn se refere à outra ponta do pipeline reativo, nos permitindo controlar em qual Scheduler o consumo dos eventos será realizado. O mesmo exemplo anterior:
Observable.create(emitter -> {
//thread em que o onNext está sendo emitido
System.out.println("Emitting on Thread " + Thread.currentThread().getId());
emitter.onNext("one");
emitter.onNext("two");
emitter.onComplete();
})
.observeOn(Schedulers.newThread()) // aqui estamos dizendo o Scheduler em que o consumo de eventos deve ocorrer
.subscribe(
value ->
//thread em que o subscribe está sendo executado
System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId())
,
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId()); //thread atual do programa
Thread.sleep(1000);
/*
output:
Emitting on Thread 1
Current thread: 1
Receive one on Thread 11
Receive two on Thread 11
Receive OnCompleted on Thread 11
*/
No exemplo acima, a emissão dos eventos ocorreu na thread atual do programa, mas o consumo dos eventos, não. O exemplo com o método just demonstra o mesmo comportamento:
Observable.just("one", "two")
.observeOn(Schedulers.newThread())
.subscribe(
value -> System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId()),
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId());
Thread.sleep(1000);
/*
output:
Current thread: 1
Receive one on Thread 11
Receive two on Thread 11
Receive OnCompleted on Thread 11
*/
Os operadores também serão executados utilizando esse Scheduler:
Observable.create(emitter -> {
//thread em que o onNext está sendo emitido
System.out.println("Emitting on Thread " + Thread.currentThread().getId());
emitter.onNext("one");
emitter.onNext("two");
emitter.onComplete();
})
.observeOn(Schedulers.newThread()) // aqui estamos dizendo o Scheduler em que o consumo de eventos deve ocorrer
.map(value -> {
//thread em que o operador map está sendo executado
System.out.println("Map, on thread " + Thread.currentThread().getId());
return value.toString().toUpperCase();
})
.subscribe(
value ->
//thread em que o subscribe está sendo executado
System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId())
,
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId()); //thread atual do programa
Thread.sleep(1000);
/*
output:
Emitting on Thread 1
Current thread: 1
Map, on thread 11
Receive ONE on Thread 11
Map, on thread 11
Receive TWO on Thread 11
Receive OnCompleted on Thread 11
*/
No post anterior, insisti bastante na característica da imutabilidade dos streams; isso também é válido para os métodos subscribeOn e observeOn. No exemplo anterior, o map devolve um novo Observable que parametrizamos com um Scheduler específico; poderíamos modificar também esse novo Observable para utilizar outro Scheduler, encadeando operações em threads diferentes:
Observable.create(emitter -> {
//thread em que o onNext está sendo emitido
System.out.println("Emitting on Thread " + Thread.currentThread().getId());
emitter.onNext("one");
emitter.onNext("two");
emitter.onComplete();
})
.observeOn(Schedulers.newThread())
.map(value -> {
//thread em que o operador map está sendo executado
System.out.println("First map, on thread " + Thread.currentThread().getId());
return "Hello, " + value;
})
.observeOn(Schedulers.newThread()) // aqui estamos modificando o Scheduler do novo Observable
.map(value -> {
//thread em que o operador map está sendo executado
System.out.println("Second map, on thread " + Thread.currentThread().getId());
return value.toString().toUpperCase();
})
.observeOn(Schedulers.newThread()) // novamente, estamos modificando o Scheduler onde os dados serão observados
.subscribe(
value -> {
System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId());
},
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId()); //thread atual do programa
Thread.sleep(1000);
/*
output:
Emitting on Thread 1
Current thread: 1
First map, on thread 11
First map, on thread 11
Second map, on thread 12
Second map, on thread 12
Receive HELLO, ONE on Thread 13
Receive HELLO, TWO on Thread 13
Receive OnCompleted on Thread 13
*/
Naturalmente, podemos combinar o subscribeOn e observeOn em um mesmo pipeline:
Observable.create(emitter -> {
//thread em que o onNext está sendo emitido
System.out.println("Emitting on Thread " + Thread.currentThread().getId());
emitter.onNext("one");
emitter.onNext("two");
emitter.onComplete();
})
.subscribeOn(Schedulers.newThread())
.observeOn(Schedulers.newThread())
.map(value -> {
//thread em que o operador map está sendo executado
System.out.println("Map, on thread " + Thread.currentThread().getId());
return "Hello, " + value;
})
.subscribe(
value ->
//thread em que o subscribe está sendo executado
System.out.println("Receive " + value + " on Thread " + Thread.currentThread().getId())
,
Throwable::printStackTrace,
() -> System.out.println("Receive OnCompleted on Thread " + Thread.currentThread().getId()));
System.out.println("Current thread: " + Thread.currentThread().getId()); //thread atual do programa
Thread.sleep(1000);
/*
output:
Current thread: 1
Emitting on Thread 11
Map, on thread 12
Receive Hello, one on Thread 12
Map, on thread 12
Receive Hello, two on Thread 12
Receive OnCompleted on Thread 12
*/
Com o Scheduler e o auxílio dos métodos subscribeOn e observeOn, é quase trivial implementarmos processamentos assíncronos e comunicação entre diferentes threads. Usando a API “pura” do Java, esse código seria extremamente difícil de ser escrito, além de vulnerável a muitos e complicados erros.
Processamento paralelo
Nos exemplos acima, introduzimos um comportamento assíncrono ao nosso código; conseguimos emitir e processar eventos em threads diferentes do segmento em que o programa está sendo executado. Mas ainda não introduzimos paralelismo ao nosso programa.
Como vimos até aqui, o conceito essencial de um stream é uma sequência de eventos ordenados no tempo; isso significa que, mesmo que nosso código processe eventos em uma thread diferente, ainda assim isso ocorrerá na ordem em que os eventos forem emitidos. Esse é o comportamento correto e esperado ao lidarmos com um stream, mas nem sempre será o desejado; na maioria das vezes, processar os eventos em ordem faz sentido para o programa, mas outras vezes, não.
Imaginemos um cenário em que os dados emitidos pelo stream são identificadores de, por exemplo, um usuário no modelo da nossa aplicação, e para cada identificador emitido queremos obter uma instância de um objeto que represente esse usuário:
Observable.fromCallable(UUID::randomUUID) //gera um UUID randomico
//apenas para exemplo: o operador repeat() re-emite os eventos do Observable original em sequência, indefinidamente
// (digamos que cada valor emitido seja o nosso id de usuário)
.repeat()
.take(10) // obtém os 10 primeiros elementos
.subscribeOn(Schedulers.newThread()) // muda o Scheduler de emissão dos eventos
.map(id -> findById(id)) // transforma cada uuid em um User
.subscribe(user -> //implementa alguma logica com o User);
O método findById(UUID id) poderia ser algo como:
private User findById(UUID id) {
// obtém um User de alguma forma, usando o id: consulta ao banco de dados, API externa, etc.
// o que nos importa aqui é que será uma operação bloqueante e lenta :(
return ...;
}
Com o subscribeOn (e o observeOn, onde fizer sentido) nós mudamos o contexto da thread de execução, mas ainda não introduzimos um processamento paralelo de fato; continuamos a processar os valores na ordem em que estão sendo emitidos, e cada processamento do operador map bloqueia a thread utilizada na emissão dos eventos. Uma possibilidade para contornarmos isso poderia ser o uso do flatMap, gerando um novo Observable para cada elemento de maneira lazy:
Observable.fromCallable(UUID::randomUUID)
.repeat()
.take(10)
.subscribeOn(Schedulers.newThread())
.flatMap(id ->
// transforma cada uuid em um Observable que emite um User
Observable.fromCallable(() -> findById(id))
)
.subscribe(user -> //implementa alguma logica com o User);
Tecnicamente, essa poderia ser uma boa solução. O operador [flatMap] transforma cada elemento em um novo Observable, se subscrevendo a todos eles para capturar os valores emitidos (que serão reemitidos no novo Observable). Ainda assim, a criação do Observable através do método fromCallable não é assíncrona, e continuamos bloqueando a thread sobre a qual o flatMap está sendo executado; podemos contornar isso, modificando o Scheduler da emissão de eventos para cada novo Observable gerado:
Observable.fromCallable(UUID::randomUUID)
.repeat()
.take(10)
.subscribeOn(Schedulers.newThread())
.flatMap(id ->
Observable.fromCallable(() -> findById(id))
.subscribeOn(Schedulers.io())) //modifica o Scheduler de cada novo Observable
.subscribe(user -> //implementa alguma logica com o User);
Conseguimos! Porém… essa é uma abordagem que funciona, mas parece problemática e sujeita a erros; os detalhes a respeito da execução assíncrona do pipeline estão tomando um espaço desproporcional no nosso código, obscurecendo a lógica de transformação e operação dos dados.
Como dito antes, em um caso de uso como esse, a ordem dos valores emitidos não tem muita importância. O que queremos aqui é executarmos as operações (no nosso caso, buscar os usuários pelo seu identificador) em paralelo, e depois juntarmos todos os resultados. O código acima pode ser útil, mas não seria mais simples um método equivalente ao parallel, da API de Stream do Java?
Naturalmente, o RxJava fornece uma maneira simples de fazermos isso :).
(Um pouquinho de) Flowable
A versão 2.x do RxJava introduziu um novo objeto chamado Flowable. Esse objeto é equivalente a um Observable, mas vitaminado com esteróides. Ainda vamos falar bastante e carinhosamente do Flowable nesse post; por enquanto, vamos apenas estudar como esse objeto pode nos ajudar em relação ao paralelismo.
Para nossa alegria, o Flowable possui um método chamado parallel que, como o nome indica, paraleliza o processsamento do stream; esse “modo paralelo” é representado pelo objeto ParallelFlowable (que é o retorno do método parallel). Apenas um conjunto restrito de operadores está disponível nesse objeto (map, flatMap, reduce, collect, e alguns outros).
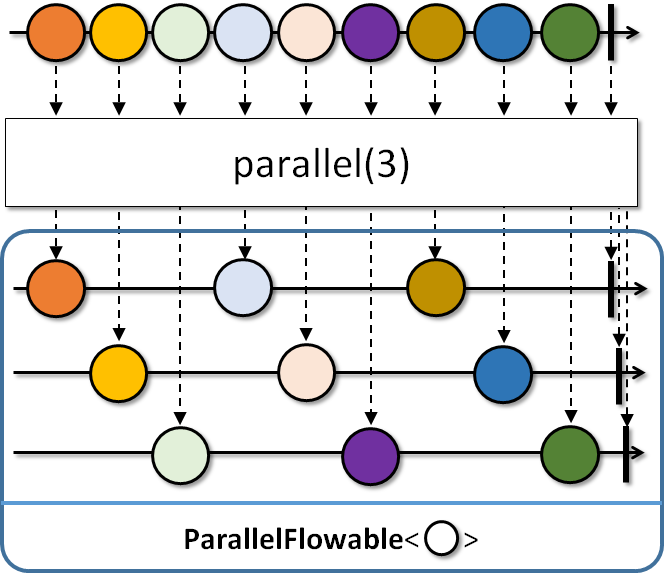
ParallelFlowable<UUID> parallel = Flowable.fromCallable(UUID::randomUUID) // Flowable ao invés do Observable
.repeat()
.take(10)
.parallel(); // esse método retorna um ParallelFlowable
parallel
// Scheduler em que o processamento paralelo será executado; sem o runOn, tudo será feito na thread corrente
.runOn(Schedulers.newThread())
.map(id -> {
//thread em que o operador map está sendo executado
System.out.println("Map [" + id + "], on thread " + Thread.currentThread().getId());
return findById(id);
})
// após fazermos o que desejávamos em paralelo, retornamos ao fluxo sequencial.
// não há garantia de ordem
.sequential()
.subscribe(user ->
//thread em que o subscribe está sendo executado
System.out.println("Receive " + user + " on Thread " + Thread.currentThread().getId())
);
/*
output:
Map [25fa8c8f-dd2d-4ec0-a23a-30a45e2c217e], on thread 11
Map [27a42c45-ca8a-4c73-9484-f7b9b9b36278], on thread 14
Map [442d2b59-bbd4-4edb-be46-565c76234546], on thread 12
Map [cb60a768-1999-45ac-8a58-9eb6fe466814], on thread 13
Map [89e41117-27c2-439b-becc-58c2c083f451], on thread 12
Receive 25fa8c8f-dd2d-4ec0-a23a-30a45e2c217e on Thread 11
Map [267b1e0b-7d8f-40f6-a628-8edb2cedc64f], on thread 13
Map [0e6fbdfe-7ae5-4c58-bb94-003e8edff8ef], on thread 14
Receive 442d2b59-bbd4-4edb-be46-565c76234546 on Thread 11
Map [6501ca4f-ebfa-4ad5-9e0f-bd4602cb41b2], on thread 12
Receive cb60a768-1999-45ac-8a58-9eb6fe466814 on Thread 11
Receive 27a42c45-ca8a-4c73-9484-f7b9b9b36278 on Thread 11
Receive 89e41117-27c2-439b-becc-58c2c083f451 on Thread 11
Receive 267b1e0b-7d8f-40f6-a628-8edb2cedc64f on Thread 11
Receive 0e6fbdfe-7ae5-4c58-bb94-003e8edff8ef on Thread 11
Receive 6501ca4f-ebfa-4ad5-9e0f-bd4602cb41b2 on Thread 11
*/
Como podemos ver, as execuções da função enviada ao operador map foram feitas em paralelo, em threads diferentes; o nível de paralelismo é, por padrão, determinado pelo número de CPUs disponíveis (momento cultural: isso pode ser obtido em Java usando Runtime.getRuntime().availableProcessors()). Se preferir, você pode determinar explicitamente o paralelismo da execução usando essa sobrecarga do método parallel.
Ao obter uma instância do ParallelFlowable, um detalhe importante comentado no código acima é o método runOn, análogo ao subscribeOn e observeOn; esse método deve ser parametrizado com o Scheduler apropriado para o processamento em paralelo, caso contrário, tudo será executado na thread corrente.
Outro método importante é o sequential:
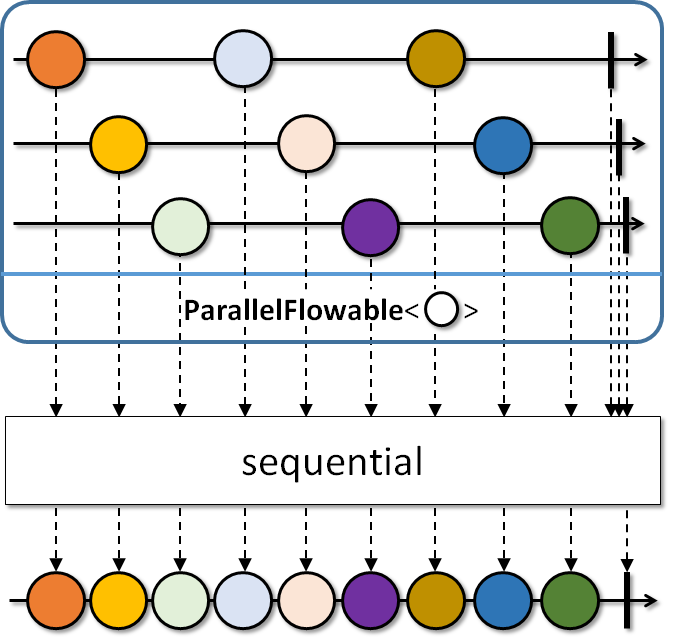
Conforme o marble diagram demonstra, esse operador irá reagrupar os elementos emitidos em diferentes threads em um nova sequência de eventos ordenados. Não há nenhuma garantia sobre a ordem dos elementos, e o novo Flowable devolvido por esse método coleta os elementos conforme eles são emitidos. O ParallelFlowable não possui o método subscribe, de modo que, para se subscrever aos eventos, você deve utilizar esse método.
Talvez nesse momento surja uma dúvida: por que o Flowable possui um “modo paralelo”, e o Observable não? Porque, na versão 2.x, apenas o Flowable suporta backpressure, que é essencial para não sobrecarregar as diferentes threads que estão sendo executadas em paralelo.
Mas o que é “backpressure”?
Backpressure
O conceito de backpressure (“contrapressão”) é um dos pilares da programação reativa, e é suportado (de uma maneira ou de outra) por todas as ferramentas que implementam esse paradigma.
Em um fluxo reativo, temos dois atores principais: um produtor (stream) e um consumidor (subscriber). Como vimos até aqui, o paradigma reativo é baseado na geração de eventos, que são empurrados para um pipeline de operações e, por fim, igualmente empurrados para o consumidor. Porém, vimos que isso pode ocorrer em diferentes threads, o que implica diferentes velocidades; o que poderia acontecer, então, se o produtor gerasse dados mais rapidamente do que o consumidor fosse capaz de processá-los? (música de desastre soando ao fundo)
Backpressure é um possível remédio para essa situação. Essencialmente, backpressure é uma maneira para que o consumidor avise ao produtor que ele não é capaz de lidar com o volume ou a velocidade dos eventos emitidos.
Considere o seguinte exemplo, baseado em um código imperativo:
Collection<String> elements = ... //obtém uma coleção de elementos de alguma forma
Iterator<String> iterator = elements.iterator();
// percorre os elementos da coleção
while (iterator.hasNext()) {
//obtém o elemento corrente da iteração;
String element = iterator.next();
//faz algo com o elemento obtido
}
O código acima fornece um backpressure “natural”, pois os dados são solicitados pelo programa (pull based); se o método next for uma operação bloqueante, o programa irá esperar que essa operação termine para que a execução continue. A coleção não gera elementos mais rapidamente do que o código é capaz de processar, pelo simples fato de que o programa os solicita um de cada vez!
Na programação reativa, o inverso acontece: o modelo de programação é push based, onde os dados são empurrados para o programa; nosso código recebe, ao invés de solicitar os dados. Considere o exemplo abaixo:
// emite um evento a cada millisegundo (!)
Observable.interval(1, TimeUnit.MILLISECONDS)
.subscribe(element -> {
try {
// aguarda dois segundos...
Thread.sleep(2000);
System.out.println(element);
} catch (Exception e) {}
});
Acima, temos um consumidor mais lento do que a emissão de eventos. Nesse código, não ocorreria problema nenhum, pois vimos que, a não ser que digamos o contrário, a publicação e o consumo dos eventos ocorrem na mesma thread. Então, o primeiro onNext é bloqueado até que o evento seja consumido pelo subscriber, e só após isso o segundo evento é emitido, e assim sucessivamente. Se houvesse outro Scheduler envolvido no consumo dos eventos (via observeOn), nosso programa ainda funcionaria… até o momento em que fosse encerrado com um erro do tipo OutOfMemoryError!
Não queremos que isso aconteça, certo? Queremos que, em momentos de pico, nosso software seja capaz de continuar a processar e responder. Em outras palavras, queremos que nosso software seja resiliente. Mas como?
Backpressure in action :)
Como comentamos antes, o Flowable é o objeto que tem suporte a backpressure. Vejamos o código abaixo:
Flowable.interval(1, TimeUnit.MILLISECONDS)
.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(2000);
System.out.println(element);
} catch (Exception e) {}
});
O código acima irá gerar uma exceção do tipo MissingBackpressureException. Essa exceção indica exatamente a situação que temos em mãos e que vimos acima: o produtor tentou emitir um evento que o consumidor não é capaz de processar. Na versão 1.x do RxJava, o Observable também lançava essa exceção caso o consumidor fosse sobrecarregado, mas esse é um problema um tanto quanto obscuro e talvez inesperado. Afinal, nós vimos que o Flowable suporta backpressure, mas a exceção indica que o backpressure está “ausente”. Por que? Porque não definimos a política do que deve ser feito caso o volume de eventos seja maior do que o tamanho da pilha interna, que por padrão é 128 elementos (esse valor é configurável e pode ser sobrescrito, inclusive para cada operador através de sobrecargas dos métodos, mas também é possível configurar o tamanho da pilha globalmente).
Esse é um detalhe interessante, pois o backpressure nos dá o poder de implementarmos um comportamento a respeito dos eventos adjacentes. Afinal de contas, mesmo que o consumidor não seja capaz de processá-los, eventos estão sendo gerados; sem o backpressure, essa sobrecarga iria estrangular nosso programa, mas agora temos as ferramentas para decidir o que deve ser feito.
Para começarmos, podemos converter nosso Observable em um Flowable, com o método toFlowable.
Flowable flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(???)
Esse método recebe como parâmetro um BackpressureStrategy, que é um enum com as políticas possíveis de backpressure que podem ser aplicadas, e que vamos analisar abaixo.
Políticas de backpressure
missing
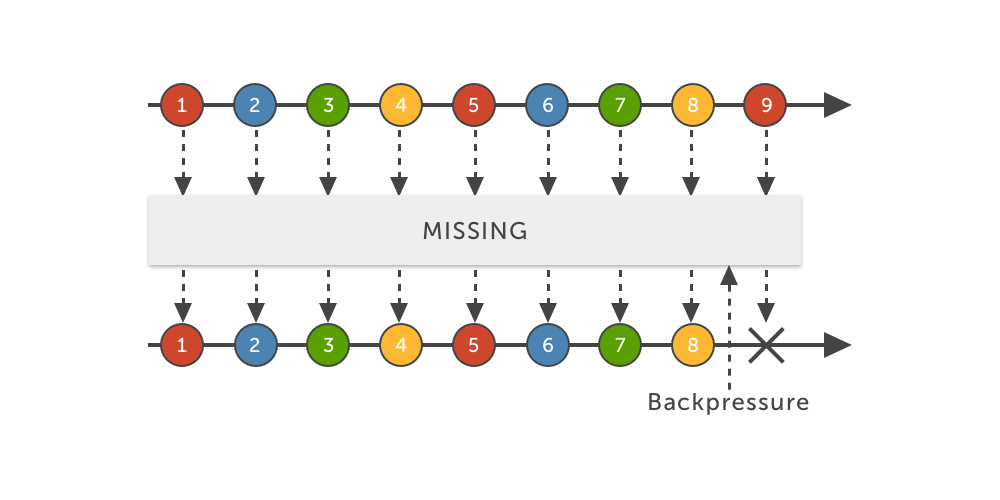
Com a estratégia MISSING, basicamente desligamos o backpressure do Flowable criado. Eventos são emitidos respeitando o tamanho da pilha, e o consumidor deve lidar com qualquer sobrecarga. E se ele não conseguir? Adivinhe: MissingBackpressureException.
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING);
flowable.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(2000);
System.out.println(element);
} catch (Exception e) {}
});
/*output:
io.reactivex.exceptions.MissingBackpressureException: Queue is full?!
*/
Mas haveria alguma motivação para utilizarmos essa estratégia, desabilitando o backpressure? Sim, como veremos mais adiante.
error
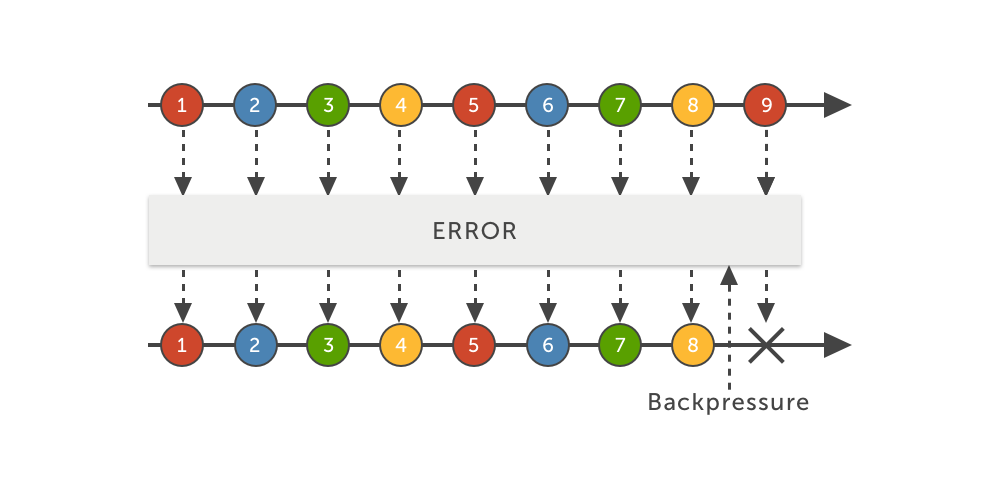
A estratégia ERROR, como o nome indica, irá lançar uma exceção do tipo MissingBackpressureException caso o consumidor não consiga mais processar eventos. Ela é útil caso queiramos que nosso subscriber seja imediatamente notificado sobre essa situação e possa reagir de acordo.
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.ERROR);
flowable.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(2000);
System.out.println(element);
} catch (Exception e) {}
});
/*output:
io.reactivex.exceptions.MissingBackpressureException: could not emit value due to lack of requests
*/
buffer
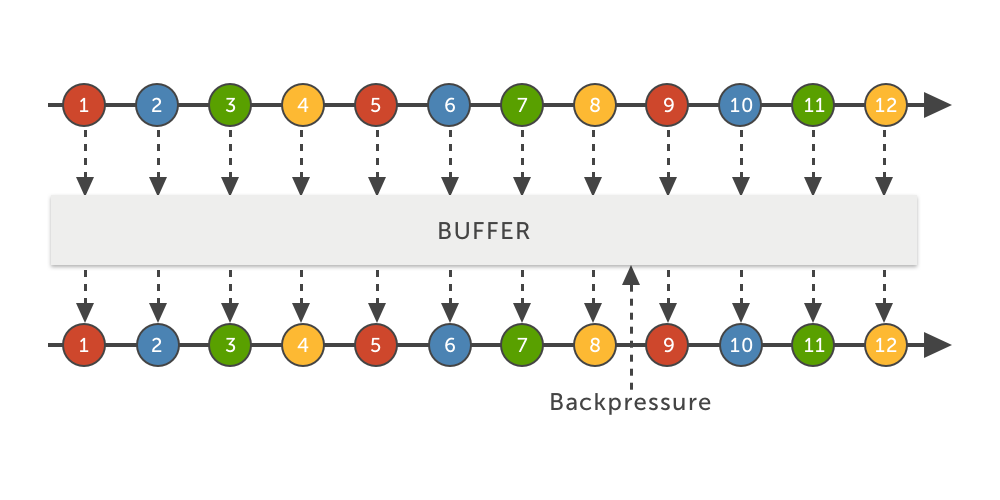
O BUFFER irá configurar o Flowable para armazenar os eventos até que eles possam ser consumidos.
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.BUFFER);
flowable.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(2000);
System.out.println(element);
} catch (Exception e) {}
});
/*output:
1
2
...
*/
No exemplo acima, não há MissingBackpressureException; os eventos são armazenados até que o subscriber possa processá-los. Naturalmente, o buffer também possui um tamanho limitado. O que acontecerá quando o limite de eventos armazenados for atingido? Continue lendo! :)
drop
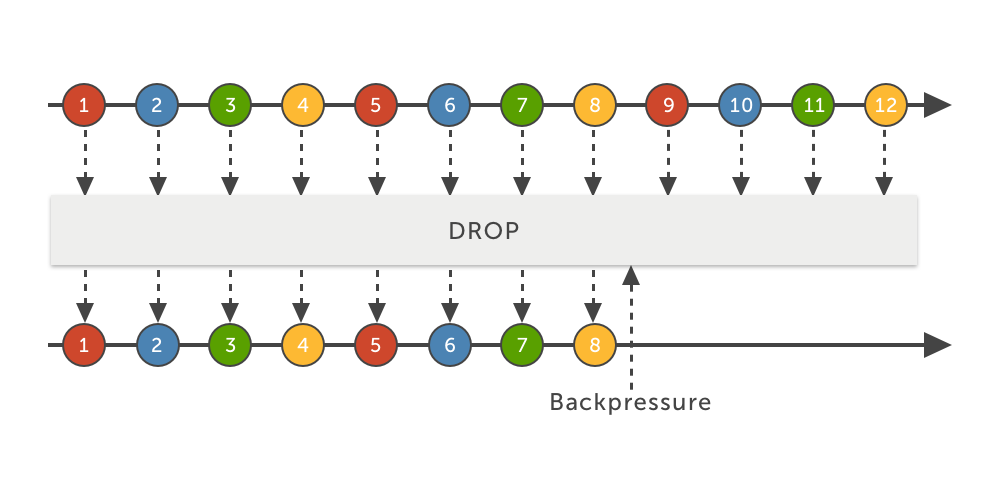
Outra abordagem possível é simplesmente descartar os eventos excedentes, e essa estratégia é o DROP. Essa estratégia irá descartar todos os eventos posteriores ao momento em que o tamanho máximo da pilha foi alcançado, até que o subscriber sinalize que pode voltar a processá-los (e os eventos voltarão a ser consumidos a partir desse momento):
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.DROP);
flowable.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(100);
System.out.println(element);
} catch (Exception e) {}
});
/*output (essa saída certamente irá variar):
1
2
3
...
125
127
...
9870 (os valores anteriores foram descartados!)
*/
O output da execução acima certamente será diferente caso você execute esse código, mas em algum ponto da sequência você perceberá que vários valores foram simplesmente “pulados” (na minha execução, a saída pulou do valor 127 para o 9870!); na verdade eles foram apenas descartados pelo Flowable. Essa estratégia é útil caso você possa se dar ao luxo de perder elementos; afinal, dependendo do caso de uso, pode ser melhor conseguir lidar com alguns eventos do que com evento nenhum (que é o que acontecerá caso sua aplicação caia!).
latest
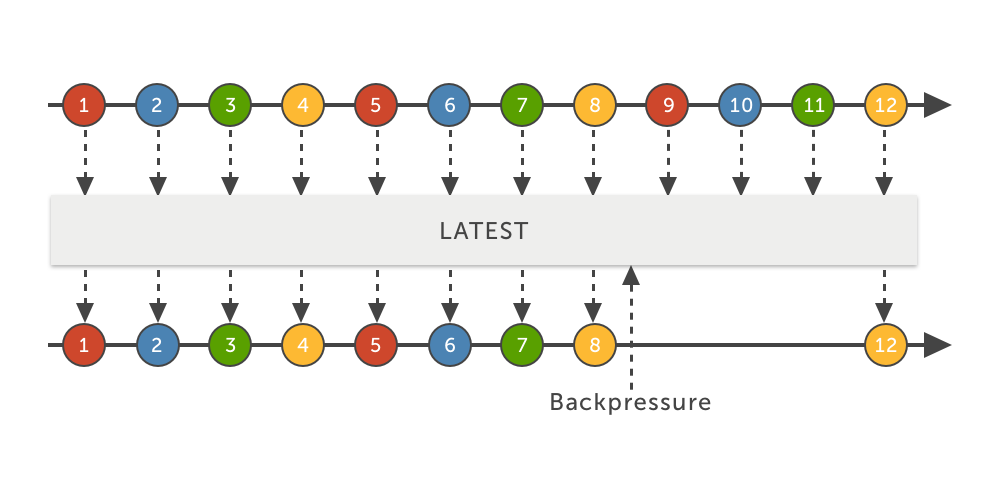
Por último, o LATEST, que é sutilmente diferente do DROP. O detalhe é que essa estratégia garante que o último evento adicional não será descartado. A estratégia DROP não tem essa preocupação, descartando todos até que o consumidor possa voltar a consumí-los.
onBackpressureXXX
O Flowable possui alguns métodos que permitem configurar diretamente a política de backpressure no próprio objeto. Esse é um caso de uso para a estratégia MISSING; pode fazer sentido você utilizar essa estratégia ao converter um Observable para um Flowable, e depois utilizar um desses métodos para configurar explicitamente como se dará o backpressure dentro do pipeline reativo.
onBackpressureBuffer
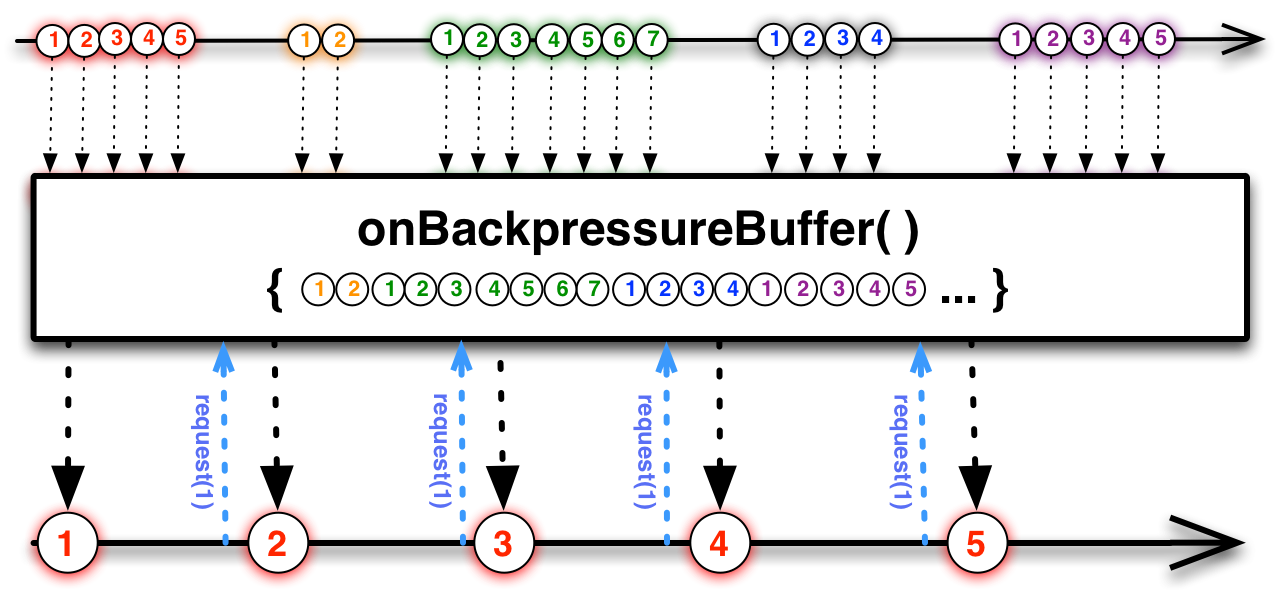
Equivalente à estratégia BUFFER: esse método irá configurar o Flowable para armazenar os eventos até que eles possam ser consumidos. A saída será a mesma do exemplo anterior:
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING); //desliga o backpressure - será configurado abaixo
flowable.onBackpressureBuffer()
.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(2000);
System.out.println(element);
} catch (Exception e) {}
});
/*output:
1
2
...
*/
Esse método tem sobrecargas que podem ser úteis em diversos casos de uso, como customizar o tamanho da pilha do buffer, executar uma função caso o buffer seja excedido, ou para um ajuste ainda mais fino, definir uma estratégia sobre o que deve ser feito quando o limite do buffer for alcançado.
onBackpressureDrop
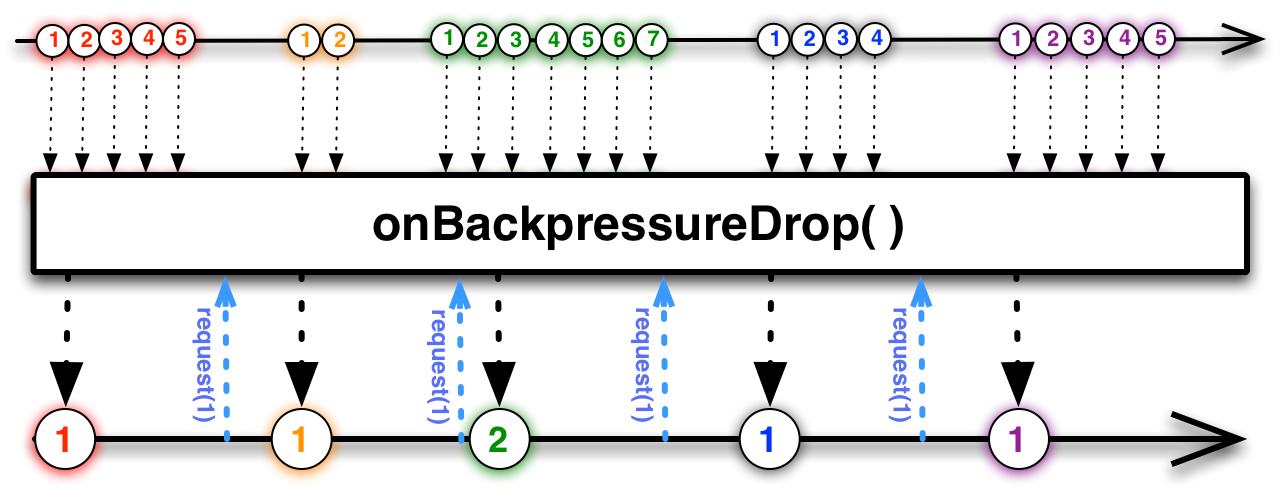
Equivalente à estratégia DROP: eventos excedentes serão descartados.
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING);
flowable.onBackpressureDrop()
.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(100);
System.out.println(element);
} catch (Exception e) {}
});
/*output (essa saída certamente irá variar):
1
2
3
...
125
127
...
9870 (os valores anteriores foram descartados!)
*/
Também existe uma sobrecarga que permite executar uma função que recebe os valores descartados.
onBackpressureLatest
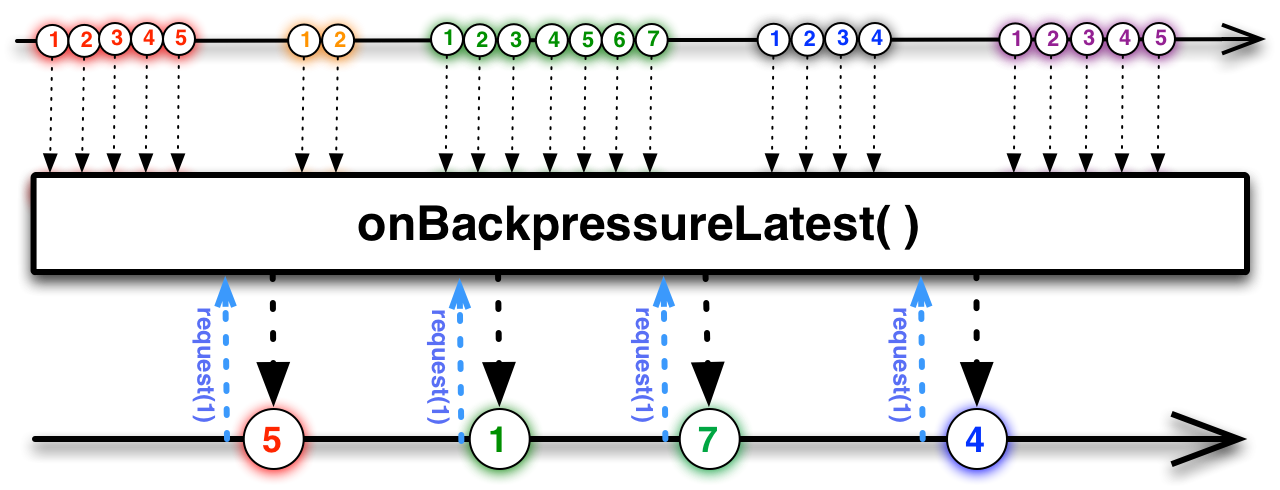
Equivalente à estratégia LATEST, com as mesmas considerações comentadas mais acima a respeito da estratégia BackpressureStrategy.LATEST.
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING);
flowable.onBackpressureLatest()
.observeOn(Schedulers.newThread())
.subscribe(element -> {
try {
Thread.sleep(100);
System.out.println(element);
} catch (Exception e) {}
});
Backpressure em detalhes
O fato de o produtor gerar mais valores do que o consumidor pode processá-los não é de forma alguma um “problema”, mas uma realidade com a qual nosso software deve lidar. O mecanismo de backpressure nos permite implementar um controle sobre os cenários em que isso ocorre, mas eventualmente podemos lidar com isso de outras maneiras. A ideia principal aqui é controlarmos o volume de eventos recebidos pelo consumidor.
Existem outros operadores que nos permitem controlar/limitar o número de eventos enviados. Por exemplo, sample permite obter apenas o último evento dentro de um intervalo de tempo; throttleFirst, throttleLast, throttleLatest, throttleWithTimeout e debounce permitem obter elementos dentro de intervalos e sob algumas condições; window, groupBy e buffer permitem agrupar os elementos para processamento. Todos esses operadores são soluções válidas para casos de uso em que podemos controlar a taxa de eventos emitidos (e eventualmente descartar alguns), e são formas “naturais” de backpressure.
Porém, nem sempre isso é possível ou o desejado. Por exemplo, quando configuramos uma estratégia de backpressure (nos exemplos mais acima), não implementamos nenhum controle explícito sobre o volume de eventos recebidos pelo consumidor. Mas vimos que todas as estratégias de contrapressão funcionam do mesmo modo: reduzindo a quantidade de inputs enviados ao consumidor. Como isso é feito?
Reactive Streams
A versão 2.x do RxJava implementa o Reactive Streams, uma pequena especificação que surgiu do esforço de algumas empresas e da comunidade para padronização do comportamento reativo na JVM. O Reactive Streams define um pequeno conjunto de interfaces para publicação e subscrição de eventos, e tem como principal objetivo definir um modelo de funcionamento para o backpressure em conjunto com processamento não-bloqueante. O Reactive Streams também está presente no Java a partir da versão 9.
As estratégias que vimos acima são implementadas com base no comportamento definido nessa especificação, mas como realmente funcionam? Vamos olhar em detalhes agora :).
O mesmo código dos exemplos anteriores:
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING);
flowable.onBackpressureLatest()
.observeOn(Schedulers.newThread())
.subscribe(?);
O método subscribe do Flowable tem diversas sobrecargas; uma delas recebe um Subscriber do Reactive Streams como argumento.
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING);
flowable.observeOn(Schedulers.newThread())
.subscribe(new Subscriber<Long>() {
@Override
public void onSubscribe(Subscription s) {
}
@Override
public void onNext(Long t) {
}
@Override
public void onError(Throwable t) {
}
@Override
public void onComplete() {
}
});
O método onSubscribe é invocado quando uma subscrição se registra ao stream, recebendo como argumento um objeto do tipo Subscription. Esse objeto, que representa um consumidor, é responsável por controlar o volume de mensagens recebidas, através do método request(n) (nota à parte: seria extremamente raro você ter de lidar com o backpressure e a taxa de eventos diretamente, mas o exemplo irá atender nossos propósitos de estudo ;)).
Digamos que nosso consumidor seja lento o bastante para que desejemos receber uma mensagem de cada vez. O código abaixo demonstra esse mecanismo:
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING);
flowable
.observeOn(Schedulers.newThread())
.subscribe(new Subscriber<Long>() {
private Subscription subscription;
@Override
public void onSubscribe(Subscription subscription) {
//recebe o Subscription associado ao Subscriber (um Subscription só pode ser utilizado por um Subscriber)
this.subscription = subscription;
subscription.request(1); //solicita APENAS UM item ao produtor
}
@Override
public void onNext(Long value) {
//faz algo leeeento....
subscription.request(1); //solicita APENAS MAIS UM item ao produtor
}
@Override
public void onError(Throwable t) {
t.printStackTrace();
}
@Override
public void onComplete() {
System.out.println("OnComplete");
}
});
Nenhum evento é enviado ao consumidor até que o método request do Subscription seja invocado. No método onSubscribe, quando recebemos o Subscription associado ao consumidor, solicitamos um único evento ao produtor, que será processado no método onNext. Após isso, solicitamos mais um evento ao produtor; e assim sucessivamente.
Outra sobrecarga do método subscribe recebe um FlowableSubscriber, que é uma especialização do Subscriber no RxJava; vejamos o exemplo abaixo, usando um DisposableSubscriber (que implementa essa interface) :
Flowable<Long> flowable = Observable.interval(1, TimeUnit.MILLISECONDS)
.toFlowable(BackpressureStrategy.MISSING);
flowable
.observeOn(Schedulers.newThread())
.subscribe(new DisposableSubscriber<Long>() {
@Override
protected void onStart() {
request(1); //solicita APENAS UM item ao produtor (o padrão é Long.MAX_VALUE)
}
@Override
public void onNext(Long value) {
//faz algo leeeento....
subscription.request(1); //solicita APENAS MAIS UM item ao produtor
}
@Override
public void onError(Throwable t) {
t.printStackTrace();
}
@Override
public void onComplete() {
System.out.println("OnComplete");
}
});
Novamente, muito raramente você terá de lidar diretamente com essa lógica. Como vimos antes, existem meios de limitar a taxa de emissão de eventos e de controlar eventuais sobrecargas com as diferentes estratégias de backpressure. A documentação do RxJava também explica extensamente os detalhes de implementação.
Flowable em detalhes
Vamos falar um pouco mais sobre o Flowable. Como vimos antes, esse objeto é o equivalente de um Observable, mas com suporte a backpressure
Como dito acima, um dos principais objetivos do Reactive Streams é a criação de uma abstração para objetos reativos com suporte a contrapressão, e o RxJava (na versão 2.x) é uma implementação dessa especificação. Flowable implementa a interface Publisher do Reactive Streams, com todos os comportamentos definidos na especificação. Isso também torna o Flowable interoperável com outras implementações do Reactive Streams, como o Reactor ou o Akka (é comum os objetos desses frameworks interoperarem com um Publisher, assim como é o caso da maioria dos métodos do Flowable).
Flowable também tem todos os operadores reativos que vimos no post anterior, e métodos de fábrica equivalentes aos do Observer.
O suporte a backpressure torna o Flowable mais adequado para cenários de grande volume de mensagens, ou operações de I/O (acesso a disco, banco de dados, requisições HTTP). A documentação detalha bem os casos em que é mais adequado usar um Flowable ou um Observer.
Scheduler em detalhes
Agora, um pouco mais sobre o Scheduler, o principal objeto dos frameworks Rx para computação assíncrona. Aqui, é importante relembrar que o comportamento padrão dos frameworks Rx (e outros) é single thread; se quisermos implementar uma computação assíncrona, isso deve estar explicitamente expresso no código. E o Scheduler é o objeto utilizado para esse fim.
Como vimos antes, instâncias de Scheduler podem ser criadas utilizando a classe Schedulers, mas o que é esse objeto?
Um Scheduler é o objeto responsável por organizar/agendar a execução de unidades de trabalho. No caso do RxJava, essas unidades são representadas na forma de Runnables, uma interface da API padrão do Java que essencialmente representa uma computação qualquer. Essas unidades de trabalho representam um processamento isolado, que serão executadas tão rapidamente quanto possível (sem tempo de espera), ou em um determinado ponto do tempo (após um período específico ou periodicamente), dependendo do caso. O isolamento de cada unidade fornece uma abstração útil sobre a execução, permitindo que ela seja feita, de maneira uniforme, sobre qualquer modelo de execução de tarefas (síncrono ou assíncrono).
Cada unidade de trabalho é representada por um Worker, um objeto que encapsula a execução do Runnable sobre um esquema qualquer gerenciado pelo Scheduler (Threads customizadas, event loops, um Executor do Java, modelo de atores, etc). Um componente importante desse objeto é um relógio interno que fornece à tarefa uma noção do “tempo”. Isso permite algumas possibilidades interessantes, especialmente para testes que envolvem o agendamento de tarefas, pois podemos “avançar” ou “voltar” no tempo para simular o comportamento do agendador. Existe um Scheduler especial para esse propósito que veremos mais abaixo ;).
Para a construção de pipelines reativos, dificilmente você terá que manipular diretamente um Scheduler ou um Worker. Como dito antes, um dos príncipios de design dos frameworks reativos é fornecer uma fundação sólida para construção de programas que façam uso de computação assíncrona, de modo que esse trabalho é, com efeito, realizado de forma transparente. Mas existem variações do Scheduler fornecidas pelo próprio RxJava e é interessante que as conheçamos, para que possamos escolher a mais adequada para cada tipo de tarefa.
Essas implementações estão disponíveis na classe Schedulers, e vamos analisá-las com mais detalhes abaixo.
Schedulers.computation
O método Schedulers.computation devolve um Scheduler indicado para uso em tarefas orientadas a CPU (que requerem poder computacional e sem código bloqueante, como cálculos, por exemplo). Por padrão, o número de threads disponíveis será o número de cores disponíveis. Esse comportamento garante que esse Scheduler nunca irá saturar o hardware, mesmo sob carga pesada.
Schedulers.io
Schedulers.io devolve um Scheduler indicado para uso em tarefas de I/O, como requisições HTTP, acesso a bancos de dados, acesso a disco, etc. NÃO é recomendado para tarefas computacionais. Esse é o Scheduler adequado caso precise realizar I/O bloqueante de maneira assíncrona no seu pipeline.
Schedulers.newThread
Schedulers.newThread retorna um Scheduler que, como o nome indica, cria uma nova thread para cada unidade de trabalho. O cuidado a ser tomado aqui é que um número potencialmente ilimitado de threads podem ser geradas, gerando lentidão ou erros de OutOfMemoryError.
Schedulers.single
O método Schedulers.single devolve um Scheduler que irá executar suas tarefas em uma única thread, aninhada à thread corrente e bloqueando sua execução. É útil para tarefas fortemente sequenciais.
Schedulers.trampoline
O método Schedulers.trampoline é parecido com o single, mas devolve um Scheduler que irá enfileirar as tarefas e executá-las em um formato FIFO (“first-in-first-out”), de maneira sequencial e na mesma thread em que a primeira tarefa for executada. Mas não é isso que o single faz? A diferença do trampoline é que o início de uma tarefa dependerá do término da anterior, mesmo em casos que envolvem delay. Um exemplo utilizando o single:
Scheduler scheduler = Schedulers.single();
Worker worker = scheduler.createWorker();
System.out.println("Current thread: " + Thread.currentThread());
worker.schedule(() -> System.out.println("First: " + Thread.currentThread()));
//a tarefa abaixo deve esperar 1 segundo para ser executada
worker.schedule(() -> System.out.println("Second: " + Thread.currentThread()), 1, TimeUnit.SECONDS);
System.out.println("End");
Thread.sleep(2000);
/*
output:
Current thread: Thread[main,5,main]
First: Thread[RxSingleScheduler-1,5,main]
End
Second: Thread[RxSingleScheduler-1,5,main]
*/
O resultado acima demonstra que o single não bloqueia a thread para execução das tarefas que tenham um tempo de espera.
Agora o mesmo código, com o trampoline:
Scheduler scheduler = Schedulers.trampoline();
Worker worker = scheduler.createWorker();
System.out.println("Current thread: " + Thread.currentThread());
worker.schedule(() -> System.out.println("First: " + Thread.currentThread()));
//a tarefa abaixo será agendada para 1 segundo no futuro
worker.schedule(() -> System.out.println("Second: " + Thread.currentThread()), 1, TimeUnit.SECONDS);
worker.schedule(() -> System.out.println("Third: " + Thread.currentThread()));
System.out.println("End");
Thread.sleep(2000);
/*
output:
Current thread: Thread[main,5,main]
First: Thread[main,5,main]
Second: Thread[main,5,main]
Third: Thread[main,5,main]
End
*/
A saída demonstra que a thread executando as tarefas (no caso, a thread principal) ficou bloqueada até que a segunda tarefa terminasse, e depois continuou a executar as tarefas subsequentes. Essa é a diferença fundamental entre o single e o trampoline.
Schedulers.from
Caso essas configurações não atendam o seu caso de uso, também existe o método Schedulers.from, que recebe como parâmetro um Executor do Java, o qual você pode criar e parametrizar de acordo com suas necessidades.
TestScheduler
Um detalhe de implementação importante do Scheduler é o conceito de um “relógio” interno, que fornece ao agendador uma noção de “tempo”. É esse conceito que permite a criação de streams baseados em intervalos (como Observable.interval) ou operadores que trabalham com janelas de tempo (como window ou debounce). Especialmente para testes de unidade, pode ser conveniente simularmos algo como um “avanço no tempo” para reproduzirmos algum comportamento. Existe uma classe específica para esse propósito chamada TestScheduler.
Digamos, um código como esse:
//aguarda 5 segundos entre cada emissão
Observable.interval(5000, TimeUnit.MILLISECONDS)
.subscribe(System.out::println);
Se quiséssemos testar o código acima, teríamos que reproduzir o tempo de espera (no caso, 5 segundos) no nosso teste. Isso não é apenas demorado; o problema maior é que o código acima não faz realmente nada até o momento em que a janela de tempo se fecha e o evento é disparado. Mas se pudéssemos adiantar o tempo para “cinco segundos no futuro”, o código acima seria executado instantaneamente. Não podemos adiantar o relógio da máquina, mas podemos adiantar um relógio “virtual”.
TestScheduler scheduler = new TestScheduler();
Observable.interval(5000, TimeUnit.MILLISECONDS, scheduler) // utiliza o TestScheduler
.subscribe(System.out::println);
scheduler.advanceTimeBy(5000, TimeUnit.MILLISECONDS); // avança no tempo!
/*
output:
0
*/
Caso o tempo adiantado seja “maior” do que o intervalo, o Observable irá emitir os eventos normalmente (os mesmos eventos que seriam emitidos com o andar “normal” do tempo).
TestScheduler scheduler = new TestScheduler();
// intervalo de 1 segundo
Observable.interval(1000, TimeUnit.MILLISECONDS, scheduler)
.subscribe(System.out::println);
// avança cinco segundos; nesse tempo, o Observable acima teria emitido 5 eventos
scheduler.advanceTimeBy(5000, TimeUnit.MILLISECONDS);
/*
output:
0
1
2
3
4
*/
Processamento bloqueante (ou “Come To The Dark Side”)
Muito do que se diz a respeito da programação reativa se refere a processamento não-bloqueante, e, como vimos acima, os frameworks Rx fornecem uma sólida fundação para implementarmos esse tipo de lógica. O próprio modelo de programação declarativo também simplifica a implementação; ao invés do código imperativo, trabalhamos com funções que apenas recebem dados empurrados e devolvem o resultado de uma computação, e se essa função é executada em uma thread separada, é um detalhe que não afeta a escrita do código.
Mas nem sempre isso é possível ou é o desejado, especialmente no caso do Java, que é uma linguagem imperativa; muitas vezes, ao invés de enviarmos uma função que será executada quando o valor estiver disponível, precisamos do valor em si (ou eventualmente de todos os valores gerados pelo stream). Isso é especialmente verdadeiro para compatibilidade com códigos já existentes (não reativos) ou biblotecas de terceiros.
Se esse for o caso, podemos usar os operadores bloqueantes. O nome indica claramente que o processamento do stream deve ser bloqueado, porque, embora por padrão um objeto reativo seja single-thread, isso é feito implicitamente; como vimos nos exemplos acima, se quisermos tornar nosso stream assíncrono, o pipeline reativo não é afetado: será sempre push based, independente de quantas threads estiverem envolvidas. E se quisermos alterar esse comportamento para um modelo bloqueante a fim de obter um valor específico do stream, isso deve ser feito explicitamente.
Evite o uso desses métodos, pois eles quebram o conceito de push da programação reativa. Porém, para os casos onde isso seja necessário, vamos estudá-los em detalhes.
blockingFirst
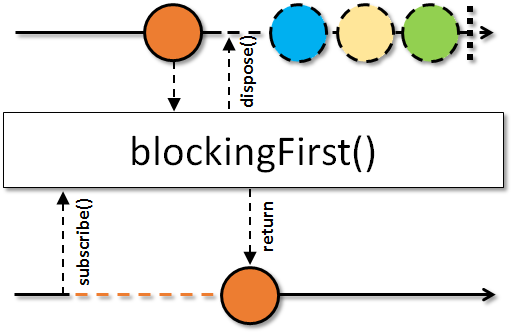
O operador blockingFirst, como o nome indica, retorna o primeiro elemento emitido pelo stream. Se nenhum item foi emitido, uma exceção do tipo NoSuchElementException será lançada. Como dito antes, o retorno desse método é o valor em si extraído do stream, e não um novo Observable como nos demais operadores reativos.
Caso necessite, use esse método com cuidado. O retorno desse método só é gerado após o evento onComplete, o que o torna perigoso para ser utilizado em streams infinitos (onde o onComplete talvez nunca seja emitido).
String first = Observable.just("one", "two", "three")
.map(String::toUpperCase)
.blockingFirst();
System.out.println("First value is: " + first);
/*
output:
First value is: ONE
*/
Como comentei, o blocking no nome do método não é um detalhe; estamos dizendo explicitamente ao Observable que o processamento deve ser bloqueado a fim de retornar o primeiro valor. No exemplo acima, não há diferença (single-thread por padrão, lembram-se?), mas digamos que nosso map esteja sendo executado em threads separadas; essas threads serão bloqueadas, pois o Observable precisa aguardar que elas terminem a fim de gerar o retorno do método. Introduzindo o observeOn no código acima, teríamos:
String first = Observable.just("one", "two", "three")
// aqui estamos dizendo ao Observable que queremos processar os elementos em outra thread
.observeOn(Schedulers.newThread())
// essa função será executada em uma thread separada
.map(String::toUpperCase)
.blockingFirst(); // para gerar o retorno desse método o Observable PRECISA aguardar as threads serem finalizadas
System.out.println("First value is: " + first);
/*
output:
First value is: ONE
*/
Existe uma sobrecarga desse operador que permite informar um valor default, caso o Observable não tenha emitido nenhum elemento (evitando o NoSuchElementException).
blockingLast
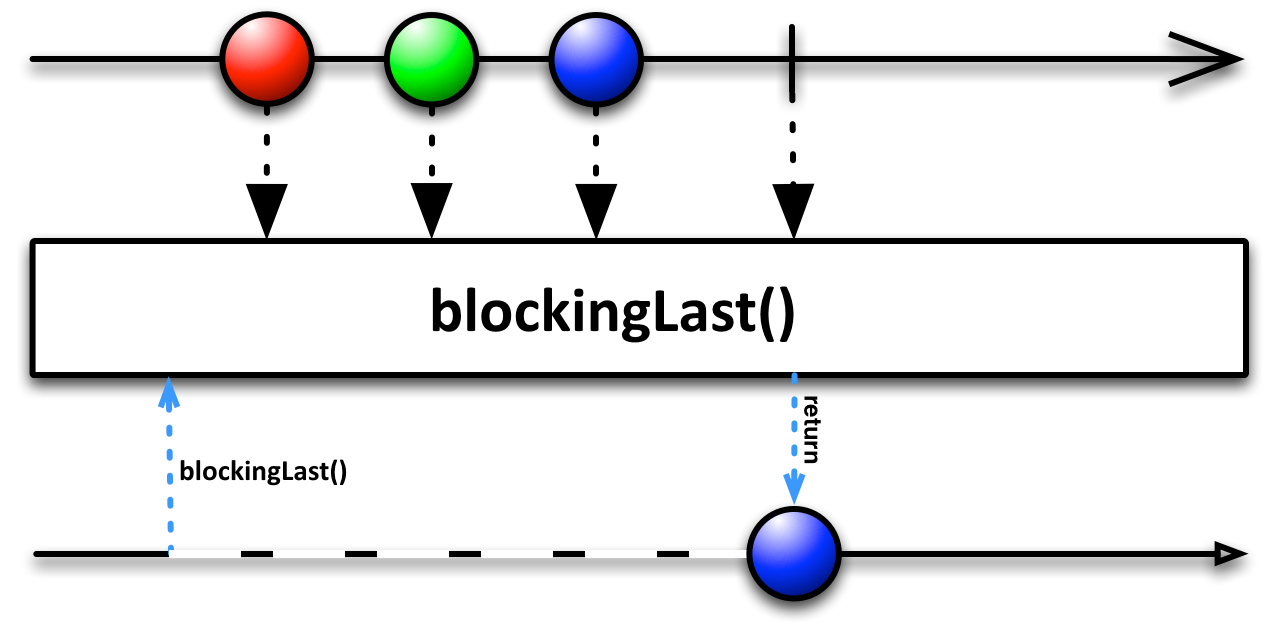
De maneira análoga, o operador blockingLast, retorna o último elemento emitido pelo stream. Se nenhum item foi emitido, uma exceção do tipo NoSuchElementException será lançada. As mesmas considerações acima sobre o blockingFirst também são válidas para o blockingLast.
String last = Observable.just("one", "two", "three")
.map(String::toUpperCase)
.blockingLast();
System.out.println("Last value is: " + last);
/*
output:
Last value is: THREE
*/
Também para esse caso, existe uma sobrecarga que permite informar um valor default, caso o Observable não tenha emitido nenhum elemento (evitando o NoSuchElementException).
blockingIterable
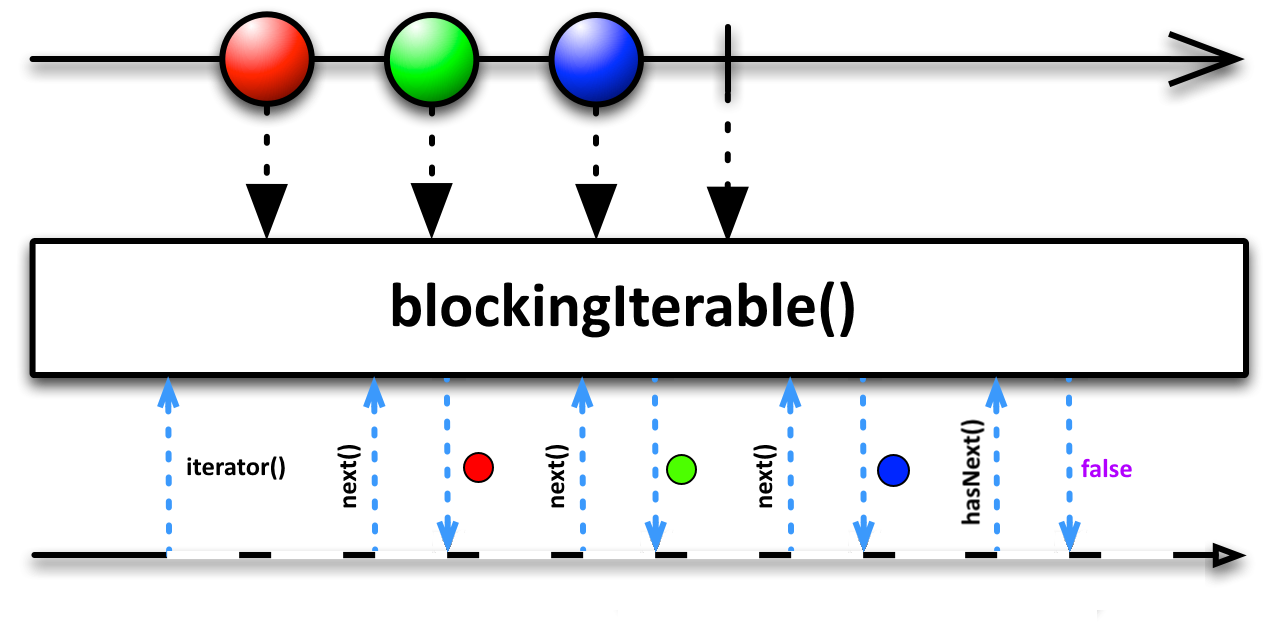
O operador blockingIterable converte o stream para um Iterable.
Iterable<String> iterable = Observable.just("one", "two", "three")
.map(String::toUpperCase)
.blockingIterable();
iterable.forEach(System.out::println);
/*
output:
ONE
TWO
THREE
*/
Novamente, o fato de ser uma operação bloqueante é relevante. Conforme o marble diagram indica, cada iteração (cada chamada ao método Iterable.next) devolve o último elemento emitido. E se nenhum item foi emitido, ou se não houver mais nenhum disponível? O Iterable ficará bloqueado aguardando o próximo evento onNext. O exemplo abaixo demonstra esse comportamento:
Iterable<Long> iterable = Observable.interval(2000, TimeUnit.MILLISECONDS) //emite um valor a cada 2 segundos
.blockingIterable();
// cada iteração irá aguardar a emissão do próximo evento
iterable.forEach(System.out::println);
/*
output:
0
1 //emitido após dois segundos
2 // emitido após dois segundos
...
*/
blockingLatest
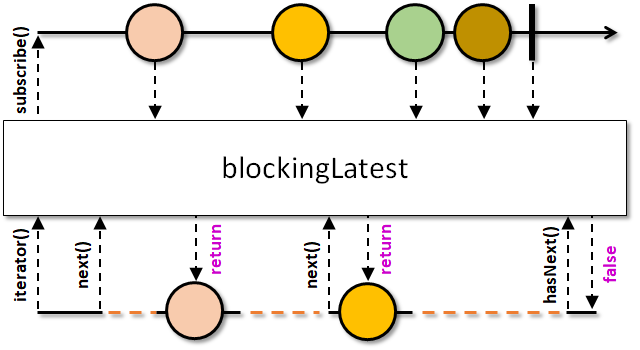
O operador blockingLatest também devolve um Iterable, onde cada iteração irá retornar o último elemento emitido. Caso nenhum item tenha sido emitido ainda, o Iterable irá aguardar o próximo evento onNext (novamente, bloqueando a thread!).
Um detalhe interessante desse operador, demonstrado no marble diagram, é o que acontece caso o stream emita eventos mais rapidamente do que as invocações do Iterable.next. Nesse caso, os eventos poderão ser descartados. Se algum onNext for imediatamente seguido de um onComplete, o último valor também pode ser ocultado.
blockingMostRecent
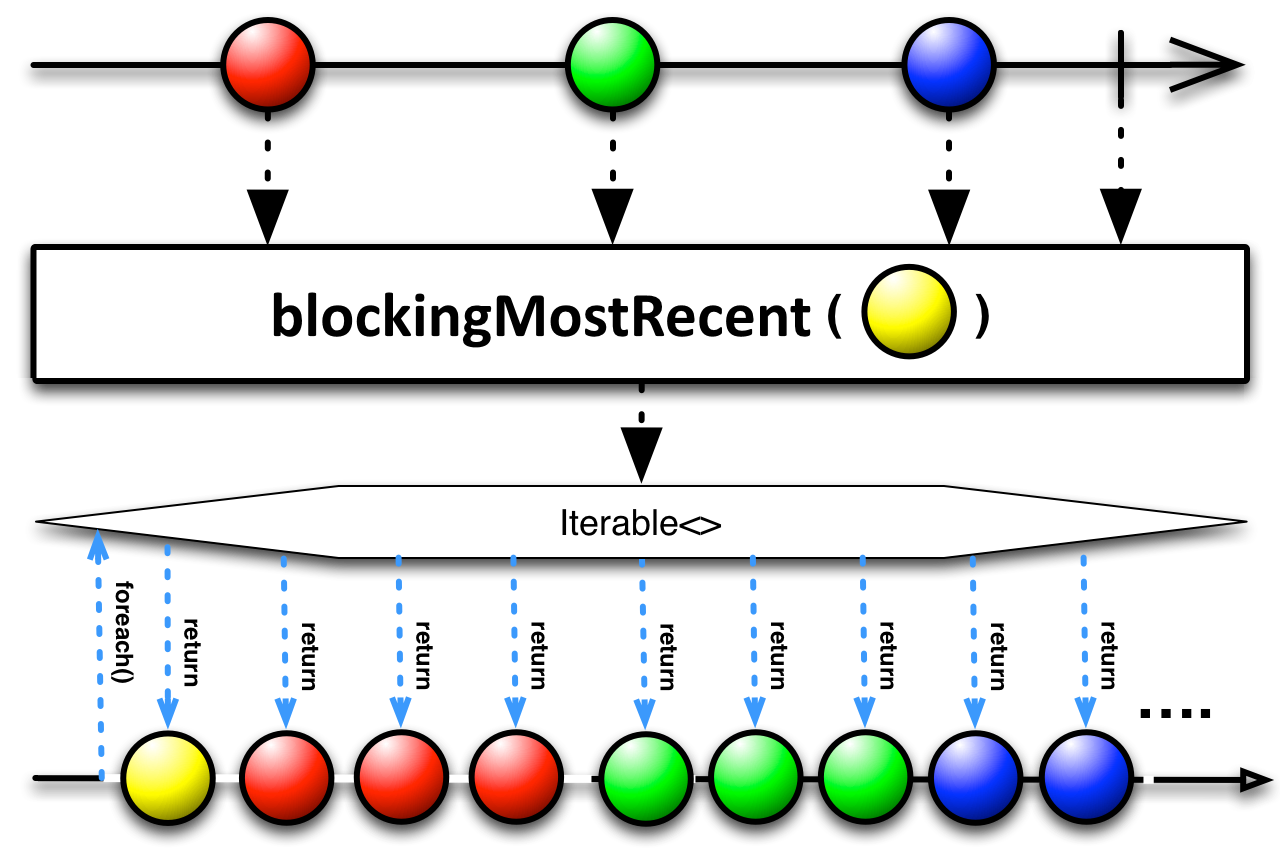
O operador blockingMostRecent também devolve um Iterable, onde cada iteração irá retornar o mais recente elemento emitido. A diferença sutil entre esse operador e o blockingLatest é que, caso nenhum elemento tenha sido emitido a cada intervalo de invocação do Iterable.next, você potencialmente terá elementos repetidos devolvidos a cada chamada do Iterable.next.
Iterable<Long> iterable = Observable.interval(2000, TimeUnit.MILLISECONDS) //emite um valor a cada 2 segundos
.blockingMostRecent(0l);
//esse parâmetro é um valor inicial que será devolvido pelo Iterable SE o stream ainda não tiver emitido nenhum elemento
iterable.forEach(value -> {
try {
Thread.sleep(1000); //demora um segundo...
} catch (InterruptedException e) {
}
System.out.println("Value: " + value);
});
/*
output:
Value: 0
Value: 0
Value: 0
Value: 0
Value: 1
Value: 1
Value: 2
Value: 2
Value: 3
Value: 3
...
*/
Naturalmente, a iteração também pode ser mais lenta do que a emissão de eventos.
Iterable<Long> iterable = Observable.interval(1000, TimeUnit.MILLISECONDS) //emite um valor a cada 1 segundo
.blockingMostRecent(0l);
iterable.forEach(value -> {
try {
Thread.sleep(2000); //demora dois segundos...
} catch (InterruptedException e) {
}
System.out.println("Value: " + value);
});
/*
output:
Value: 0
Value: 1
Value: 3
Value: 5
Value: 7
Value: 9
...
*/
blockingNext
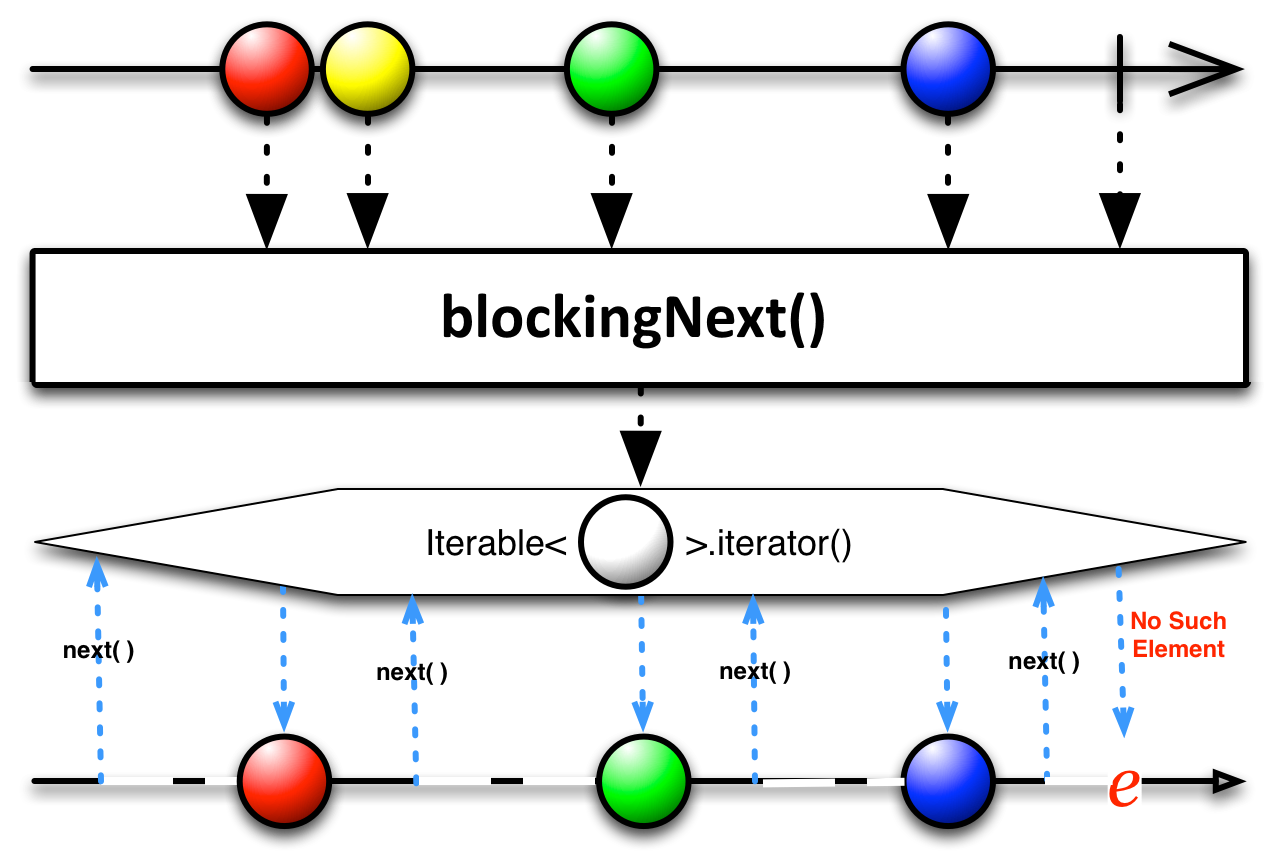
O operador blockingNext devolve um Iterable que, a cada iteração, irá aguardar a próxima emissão do evento onNext.
Iterable<Long> iterable = Observable.interval(2000, TimeUnit.MILLISECONDS)
.blockingNext();
iterable.forEach(System.out::println); //cada iteração irá aguardar dois segundos
Há uma diferença sutil entre esse operador e o blockingMostRecent. Caso não ocorram emissões de eventos entre cada iteração, ao contrário do blockingMostRecent que irá capturar o mais recente item emitido (um item potencialmente duplicado), o blockingNext irá aguardar a próxima emissão. Vejamos o mesmo exemplo mais acima do blockingMostRecent, mas usando o blockingNext.
Iterable<Long> iterable = Observable.interval(2000, TimeUnit.MILLISECONDS) //emite um valor a cada 2 segundos
.blockingNext();
iterable.forEach(value -> {
try {
//demora um segundo...
//embora o consumo seja mais rápido do que a emissão, o iterable irá aguardar a emissão do próximo valor
Thread.sleep(1000);
} catch (InterruptedException e) {
}
System.out.println("Value: " + value);
});
/*
output:
Value: 0 //não há elementos repetidos
Value: 1
Value: 2
...
*/
blockingSingle
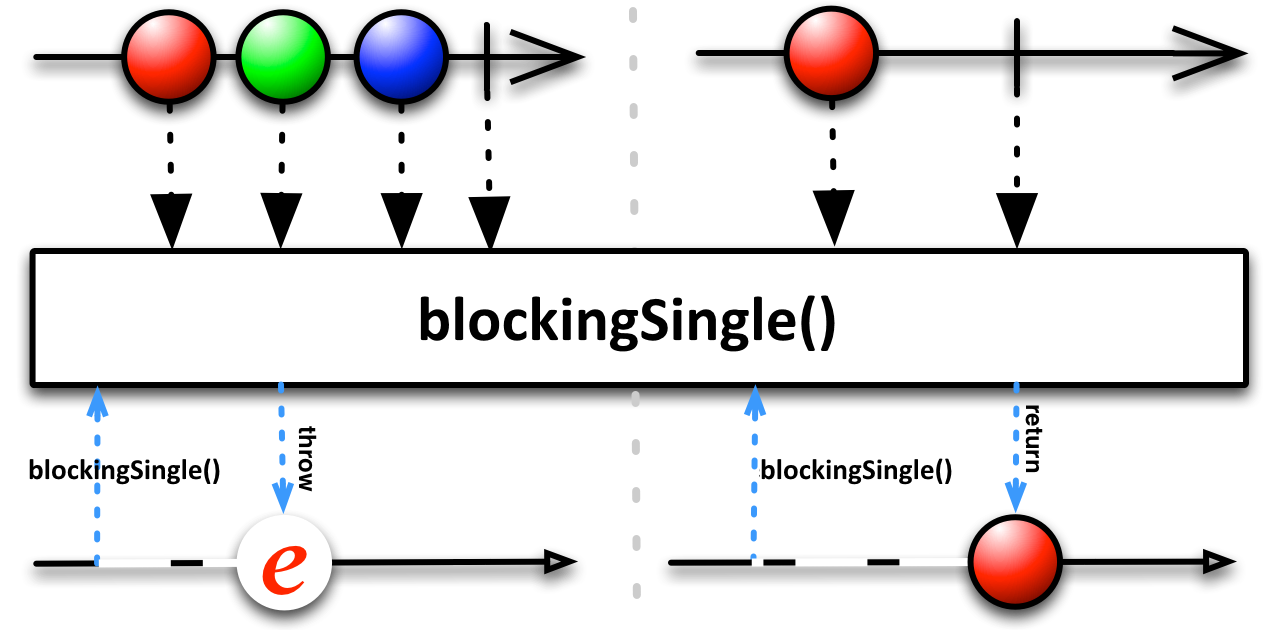
O operador blockingSingle devolve o único elemento emitido pelo stream, após ele ser completado. Se mais de um elemento foi emitido, esse método irá lançar uma exceção do tipo IllegalArgumentException. Se nenhum elemento for emitido e o stream for completado, uma exceção do tipo NoSuchElementException será lançada.
String single = Observable.just("one")
.map(String::toUpperCase)
.blockingSingle();
System.out.println(single);
/*
output:
ONE
*/
String single = Observable.just("one", "two")
.map(String::toUpperCase)
.blockingSingle();
System.out.println(single);
/*
output:
java.lang.IllegalArgumentException: Sequence contains more than one element!
*/
Object single = Observable.empty() //um Observable que completa imediatamente
.blockingSingle();
System.out.println(single);
/*
output:
java.util.NoSuchElementException
*/
Esse método tem uma sobrecarga que permite informar um valor padrão que será devolvido, caso o stream seja completado sem emitir nada.
Object single = Observable.empty()
.blockingSingle("default value");
System.out.println(single);
/*
output:
default value
*/
blockingSubscribe
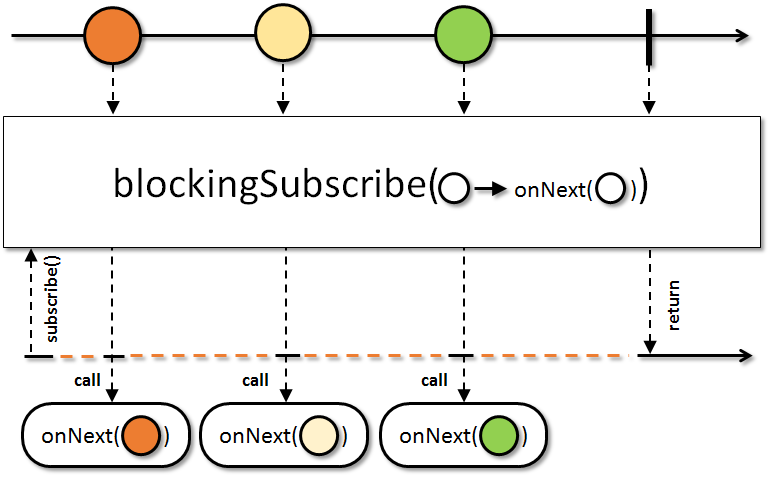
O método blockingSubscribe registra um subscription para o stream, da mesma maneira que o subscribe; porém, o consumo do evento é sempre realizada na thread corrente. É uma diferença importantíssima em relação aos comportamentos que estudamos no ínicio do post. Como vimos, os subscribers por padrão executam na mesma thread em que os eventos são publicados, e podemos customizar esse comportamento através do observeOn; os subscribers registrados pelo método blockingSubscribe, ao contrário, sempre serão executados na thread corrente do programa.
Recapitulando o comportamento não-bloqueante do Observable:
System.out.println("Current Thread: " + Thread.currentThread().getId());
Observable.just("one", "two", "three")
.observeOn(Schedulers.newThread())
.doOnNext(value ->
System.out.println("Emiting value " + value + " on the thread " + Thread.currentThread().getId())
)
.subscribe(value ->
System.out.println("Subscribing value " + value + " on the thread " + Thread.currentThread().getId())
);
/*
output:
Current Thread: 1
Emiting value one on the thread 14 //eventos emitidos em outra thread
Subscribing value one on the thread 14 //eventos consumidos na mesma thread em que foram emitidos
Emiting value two on the thread 14
Subscribing value two on the thread 14
Emiting value three on the thread 14
Subscribing value three on the thread 14
*/
E a diferença utilizando blockingSubscribe:
System.out.println("Current Thread: " + Thread.currentThread().getId());
Observable.just("one", "two", "three")
.observeOn(Schedulers.newThread())
.doOnNext(value ->
System.out.println("Emiting value " + value + " on the thread " + Thread.currentThread().getId())
)
.subscribe(value ->
System.out.println("Subscribing value " + value + " on the thread " + Thread.currentThread().getId())
);
/*
output:
Current Thread: 1
Emiting value one on the thread 14 //eventos emitidos em outra thread
Emiting value two on the thread 14
Emiting value three on the thread 14
Subscribing value one on the thread 1 //eventos consumidos na thread corrente do programa
Subscribing value two on the thread 1
Subscribing value three on the thread 1
*/
Conclusão
Nesse post, exploramos um ponto muito importante para a programação reativa: a execução assíncrona do código. Os frameworks reativos fornecem abstrações e recursos eficientes para essas complexidades, de modo que nosso código pode se concentrar nas operações do pipeline ao invés de detalhes complicados sobre programação concorrente e comunicação entre threads. Execução assíncrona e não-bloqueante do código são relevantes para escalabilidade e performance, e são uma das principais motivações para a adoção do paradigma reativo.
Após esse post, já conhecemos bem os principais conceitos e recursos envolvidos em um framework reativo. A partir do próximo post, podemos utilizar esse conhecimento para voos mais altos. Que tal vermos os conceitos de uma aplicação reativa? :)
Para quaisquer dúvidas, comentários, ou qualquer outra coisa, esteja à vontade para utilizar a caixa de comentários. Obrigado e até o próximo post!