Programação Reativa - Parte 1: O que é programação reativa?
Publicado em:
@ljtfreitas
Em tempos recentes, a expressão “programação reativa” tem ganhado (ainda mais) força nas discussões do mundo do software. Apesar de não ser algo necessariamente “novo” (nem um pouco, na verdade) e se basear em conceitos e padrões já existentes, a tal “programação reativa” tem ganho muito destaque e há um bom número de frameworks que suportam esse paradigma em diversas linguagens. Mas será apenas mais uma “buzzword” ou algo realmente útil?
Este post é o primeiro de uma série sobre programação reativa, onde queremos tentar atribuir um significado mais concreto para esse conceito, tanto a nível de implementação quanto arquitetura. Esperamos poder ajudá-lo a formar uma visão mais clara do impacto dessas idéias no seu software.
Este post é baseado na família de frameworks ReactiveX, em especial o RxJava.
Por que?
Um dos desafios da Engenharia de Software atualmente são aplicações orientadas a alto volumes de dados em tempo real. Usuários querem seus dados agora; querem ver seus tweets agora, confirmar seus pedidos agora, jogos online precisam responder agora. Agora, agora, agora!
Como desenvolvedores, nossas aplicações precisam igualmente responder a essas demandas agora. Não queremos que nosso software fique bloqueado por um pedido de informações ou aguardando o resultado de uma computação. Não queremos que nossa aplicação fique parada aguardando algum resultado, mas precisamos exibi-los assim que estiverem prontos. Se lidamos com um bloco de informações, queremos manipular resultados individuais, e não esperar que o conjunto inteiro seja processado. O comportamento das aplicações evoluiu para lidar com dados empurrados. Então, precisamos de ferramentas de implementação para construir um código capaz de reagir a eventos e informações.
Para que?
Alguns casos de uso onde a programação reativa pode fazer sentido são:
-
Eventos de UI (movimento do mouse, clicks de botão, etc): programadores desse tipo de aplicação (digamos, em Javascript ou Android) estão acostumados a lidar com eventos de componentes, então não há nada fundamentalmente diferente. As vantagens do paradigma reativo surgem com o conjunto de operadores disponíveis para manipulação dos eventos, tornando simples tarefas como, por exemplo, throttle de múltiplos clicks ou propagação de eventos para interfaces hiper-interativas;
-
Chamadas para serviços externos (REST, RPC, etc): operações realizadas sobre HTTP são bloqueantes por natureza; ao fornecer uma simplificação para o código assíncrono, a programação reativa pode ajudá-lo a desbloquear o código de cliente HTTP, mas essa é a parte mais simples. Em arquiteturas de serviços distribuídos (como microserviços), é comum um código de back-end construir uma composição entre várias chamadas dependentes (o serviço “a” é invocado, e a resposta é utilizada como parâmetro para invocar o serviço “b”, e sucessivamente). Frameworks reativos podem ajudar a orquestrar chamadas dependentes de maneira natural, com a vantagem de NÃO bloquear o código no cliente.
-
Consumo de mensagens: processamento de mensagens com alta concorrência é um caso de uso comum. Declaradamente, frameworks como o próprio RxJava, Reactor ou o Akka alegam serem capazes de processar milhões de mensagens por segundo na JVM sem esforço. Sendo isso verdade ou não, em maior ou menor grau, novamente sua implementação pode se beneficiar das ferramentas disponíveis nesses frameworks para construir um pipeline de consumo de eventos/mensagens de maneira muito simples.
-
Abstração sobre processamento assíncrono: esse detalhe vai depender da ferramenta e da linguagem que estiver utilizando (no presente post, Java :)), mas um dos pontos-chave dos frameworks reativos é fornecer uma fundação simples para processamento assíncrono, desafogando sua aplicação dos detalhes mais complexos envolvendo multithreading e permitindo que seu código possa se concentrar na lógica de manipulação dos eventos.
O que é programação reativa?
Não é o objetivo deste post cravar a “definição definitiva” sobre o assunto. Ainda assim, para uma resposta inicial à pergunta acima, podemos declarar que programação reativa é um modelo de programação sobre fluxos de dados, potencialmente assíncronos, em combinação com consumo/roteamento de eventos e propagação de estado.
No decorrer do post, vamos desconstruir essa frase, começando com…
“Fluxos de dados, potencialmente assíncronos”
Os conceitos que declaramos acima (“fluxos de dados”, “consumo de eventos”) não são exatamente novos. Frameworks/modelos orientados a eventos (por exemplo, ferramentas de “event bus” ou simples listeners de clicks do mouse) são, com efeito, implementados sobre sequências assíncronas de acontecimentos, a partir dos quais podemos produzir ações e efeitos colaterais reagindo aos eventos, quando acontecem.
A programação reativa parte da mesma idéia, mas anabolizada com esteróides :). Pode-se dizer que a programação reativa é uma versão extendida e mais poderosa do padrão Observer. Dada a premissa de termos objetos observáveis como porta de entrada do programa, um dos pilares do modelo reativo é a idéia que “fluxos de dados” (que passaremos a chamar de streams) possam ser criados a partir de qualquer coisa: variáveis discretas, entradas de dados, propriedades da aplicação, ou como nos exemplos citados antes, eventos de UI ou entradas de aplicações externas…o importante a destacar aqui é que, independente de como a entrada do stream é construída, o código de manipulação dos eventos é o mesmo. Por exemplo, seu feed do Twitter, ou o listener de um tópico do Kafka, poderiam ser consumidos da mesma maneira que o click de um botão. O stream passa a ser apenas a abstração de uma origem de dados (potencialmente (e principalmente!) assíncronos), que emite valores de forma contínua, sobre os quais você pode reagir de acordo.
Os frameworks reativos fornecem uma espetacular caixa de ferramentas para manipulação de streams; podemos filtrá-los, transformá-los, combiná-los, entre outras dezenas de operações, que veremos no decorrer do post.
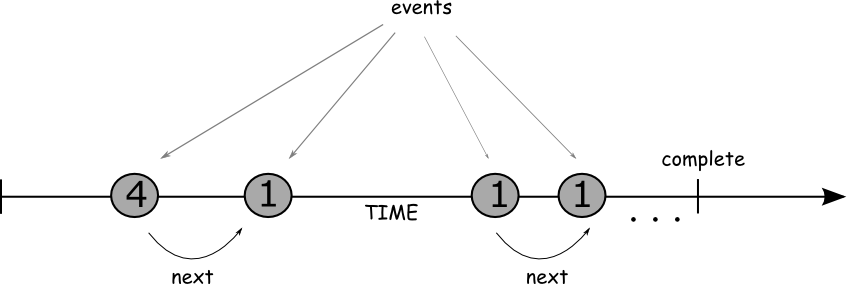
Se a idéia de “streams” é central na programação reativa, pode ser útil uma definição mais formal: um stream é uma sequência de eventos ordenados no tempo. Isso significa que, uma vez vinculado à uma fonte de dados, o stream poderá emitir três eventos: algum valor, algum erro, e no caso de uma sequência finita, um evento indicando que o stream foi concluído. Esses eventos são chamados, respectivamente, de onNext, onError e onCompleted.
Nos frameworks ReactiveX, o principal objeto que representa um stream é o Observable. Esse objeto contêm os principais operadores reativos, que iremos examinar com mais detalhes no decorrer do post.
Outro objeto importante é o Single, que representa um stream que emite apenas um valor, ou apenas um erro. Também existe o Completable, que é um stream que não emite valores, apenas indicando conclusão ou erro. A versão 2 do RxJava, que falarei mais à frente, introduziu dois novos objetos: Maybe, um observável que opcionalmente emite um valor (ou um erro) e se encerra, e o Flowable, que é um observável um pouco mais poderoso (!).
Uma vez definido nosso stream, representado por um Observable (ou alguma especialização), o próximo passo é reagirmos ao eventos emitidos pela sequência de eventos. Ou seja, precisamos de um “observador”; na programação reativa, a ação de vincular-se à um Observable é chamada de subscription, e esse papel é desempenhado por um subscriber (no caso do RxJava, o objeto que representa esse conceito é o Observer, que raramente precisa ser manipulado diretamente). O método que realiza essa operação é o subscribe, que tem várias sobrecargas para permitir variações no tratamento dos eventos onNext, onError e onCompleted.
Abaixo, alguns exemplos de criação de Observables vinculados à um Subscriber, usando os principais métodos de fábrica:
// cria um Observable, com uma expressão lambda do tipo ObservableOnSubscribe
Observable.create(emitter -> {
//emitter é um argumento do tipo ObservableEmitter
//essa função é executada quando um Subscriber se vincula ao Observable
//emite valores para os Subscribers vinculados a esse Observable
emitter.onNext("first");
emitter.onNext("second");
emitter.onNext("third");
//finaliza o Observable
emitter.onComplete();
})
.subscribe(System.out::println); //vincula um Subscriber ao Observable; a funcão enviada como parâmetro é a ação executada no evento onNext
/*
output:
first
second
third
*/
// cria um Observable a partir de um range arbitrário de dados
Observable.range(0, 5)
.subscribe(System.out::println);
/*
output:
0
1
2
3
4
*/
// cria um Observable a partir de valores arbitrários
Observable.just("first", "second", "third")
.subscribe(System.out::println);
/*
output:
first
second
third
*/
// cria um Observable vazio, que emite apenas onCompleted
Observable.empty()
.subscribe(
System.out::println, //onNext
Throwable::printStackTrace, //onError
() -> System.out.println("OnCompleted")); //onCompleted
/*
output:
onCompleted
*/
// cria um Observable que emite apenas onError
Observable.error(new RuntimeException("oops"))
.subscribe(
System.out::println, //onNext
Throwable::printStackTrace, //onError
() -> System.out.println("OnCompleted")); //onCompleted
/*
output:
java.lang.RuntimeException: oops
at com.elo7.sample.rx.RxJavaSample.main(RxJavaSample.java:8)
*/
// cria um Observable que não emite nenhum evento
Observable.never()
.subscribe(
System.out::println, //onNext
Throwable::printStackTrace, //onError
() -> System.out.println("OnCompleted")); //onCompleted
// o código acima não produz nenhuma saída
// semelhante ao Observable.create, mas permite declarar dinamicamente como o Observable deve ser criado a cada subscrição
// o argumento é um java.util.concurrent.Callable<? extends ObservableSource<? extends T>>.
Observable<String> observable = Observable.defer(() -> (e) -> e.onNext("hello"));
observable.subscribe(System.out::println);
observable.subscribe(System.out::println);
/*
output:
hello
hello
*/
Observable é um ObservableSource, de modo que o Observable gerado no método defer pode utilizar outro Observable como fonte de dados. Como exemplo, suponhamos um cenário onde você deseja emitir aos subscribers o timestamp do momento da subscrição. Uma implementacao com o método just poderia ser:
Observable<Long> observable = Observable.just(System.currentTimeMillis()); //o Observable é criado com este valor
observable.subscribe(System.out::println);
Thread.sleep(1000);
observable.subscribe(System.out::println);
/*output: ambos os subscribers receberam o mesmo valor
1510599123864
1510599123864
*/
Com o defer, podemos adiar o código que é executado no onSubscribe:
Observable<Long> observable = Observable.defer(() -> Observable.just(System.currentTimeMillis()));
observable.subscribe(System.out::println);
Thread.sleep(1000);
observable.subscribe(System.out::println);
/*
output: diferentes timestamps
1510599357278
1510599358291
*/
Um detalhe relevante que ainda não abordamos é a questão dos “streams assíncronos”, que, com efeito, é um dos motivos do hype em geral sobre a programação reativa. Frameworks reativos como RxJava suportam multithreading de maneira simples e natural (como veremos), o que eventualmente pode levar alguns desenvolvedores a inferir que “tudo” é feito de forma assíncrona. Isso não é verdade!. É importante deixar claro que TODOS os frameworks Rx são single-threaded por padrão, por uma questão de economia de recursos do hardware. Se um comportamento assíncrono é necessário, isso deve ser configurado explicitamente.
“em combinação com consumo/roteamento de eventos”
O modelo de objetos comentado acima (a idéia de utilizar o stream como elemento base para consumo de dados/entradas/eventos) fundamenta um dos principais conceitos da programação reativa. Na maioria dos softwares, escritos sobre o paradigma da programação imperativa, os programas são sequências de instruções bloqueantes, executadas de maneira incremental e na ordem em que foram escritas no código. No paradigma reativo, por outro lado, uma vez construído o mecanismo-fonte de dados (o stream), podemos realizar muitas (sim, muuuuuitas) operações de transformação, filtro, combinação, agrupamento, sobre esses dados.
A característica comum a TODAS essas operações é que todas elas retornam um novo stream; essa propriedade é chamada de imutabilidade. E, como comentamos acima, podemos vincular um observador para reagir às sequências de dados emitidas pelo Observable. A principal vantagem dessa abordagem é que os observadores são independentes uns dos outros, de modo que podem ser executados em paralelo ou em qualquer ordem.
O impacto disso no código é que a implementação pode seguir uma abordagem declarativa, onde nos concentramos no que o código deve fazer, e não em como deve fazer. Para fins de comparação, um pequeno exemplo demonstrando essa diferença:
Um código imperativo:
//realiza alguma computação no método doSomething(), retorna um resultado e atribui a varíavel "var"
var = doSomething();
//fazemos alguma coisa com "var"...
E um código reativo:
// definimos uma função para representar a operação onNext
myOnNext = {value -> /* Faz alguma coisa com o valor, atribuído à variável "value"*/ }
//cria o Observable de algum modo
myObservable = createObservable();
//associa o myOnNext (subscriber) ao Observable
myObservable.subscribe(myOnNext);
//continua o programa...
O exemplo acima é interessante por hora, mas não demonstra muito mais do que o observer pattern implementado de uma maneira diferente. O verdadeiro poder está nos métodos disponíveis na classe Observable; os operadores reativos. Como comentado acima, existem dezenas de operadores para os mais variados casos de uso, como criação (create, defer, empty/never/throw, from, just, range, timer, e outros), transformação (buffer, flatMap, groupBy, map, scan, window), filtro (filter, distinct, first, last, take, e outros), combinação (and/then/when, merge, join, zip, e outros), tratamento de erros (catch e retry), utilitários (delay, do, subscribe, observeOn, timeout, e outros), além de métodos para operações condicionais, operações matemáticas, conexão de streams, e vários outros.
Com esse riquíssimo conjunto de operações, torna-se simples implementarmos o consumo/roteamento de eventos, a partir de fluxos de dados: basta conectarmos esses operadores ao nosso Observable.
“…e propagação de estado.”
Como comentado antes, os operadores reativos representam operações imutáveis que retornam um novo stream (afetado pela operação em questão), ao invés de modificar o original. Isso simboliza o terceiro ponto-chave da programação reativa: a propagação de estado.
Nesse contexto, a propagação de estado nada mais é que a emissão de um valor pelo stream. Esse valor não representa apenas um dado qualquer, mas sim que algo aconteceu, e a ocorrência desse evento é propagado para os subscribers interessados em recebê-lo. Isso implica que os recebedores dos eventos lidarão sempre com o último valor emitido e sempre estarão online em relação ao stream.
Esses valores também podem ser manipulados, como comentado acima. Podem ser combinados à outras mensagens, agrupados, filtrados, remapeados, etc, mas a mensagem original nunca será modificada, e sim transformada e propagada dentro do fluxo reativo, seja para a criação de um novo stream (através dos operadores) ou para noficação dos subscribers.
Conclusão
Nesse post, apresentamos os principais fundamentos que formam a idéia da “programação reativa”, apresentando especialmente o que é um stream, e os eventos que podem ser emitidos por um fluxo de dados (onNext, onError, onCompleted).
No próximo post, uma vez esclarecidos esses conceitos, poderemos colocar mais a mão na massa com mais exemplos do espetacular RxJava!
Obrigado e qualquer dúvida, crítica ou comentário, esteja à vontade para usar a caixa de comentários!