
Introdução ao Change Data Capture (CDC)
Publicado em:
@sardinha
A atual popularidade do termo Big Data veio acompanhada de diversas buzzwords, entre elas o Change Data Capture, ou simplesmente CDC. Porém esse design pattern é tão antigo quanto os RDBMS, pois os dois estão estritamente ligados.
Como o próprio nome diz, o CDC nada mais é do que uma forma de capturar as mudanças nos dados. Vamos imaginar a seguinte tabela de produto:
CREATE TABLE `produto` (
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
nome VARCHAR(30) NOT NULL,
preco DECIMAL(15,2) NOT NULL,
quantidade INT NOT NULL,
data_atualizacao DATETIME
);
com o seguinte insert:
INSERT INTO `produto` (nome, preco, quantidade, data_atualizacao) VALUES ('Amigurumi do Batman', 79.99, 30, now());
| id | nome | preco | quantidade | data_atualizacao |
|---|---|---|---|---|
| 1 | Amigurumi do Batman | 79.99 | 30 | 2019-06-01 15:30:00 |
Suponhamos que o vendedor queira atualizar o valor do produto para 59.99. Após a operação de update, teremos o seguinte estado:
UPDATE `produto` SET preco = 59.99 WHERE id = 1;
| id | nome | preco | quantidade | data_atualizacao |
|---|---|---|---|---|
| 1 | Amigurumi do Batman | 59.99 | 30 | 2019-06-02 19:27:00 |
Até aí nenhuma novidade, correto? Agora imagine que queremos tirar algumas métricas com base nessa tabela, tais como:
- Diferença de valor quando o preço é alterado
- Velocidade em que o estoque diminui
- Qual horário um produto é mais cadastrado/atualizado
Apenas com a tabela produto não seria possível, pois sempre armazenamos o último estado do registro, mas não suas alterações.
Para resolver esse tipo de problema, foram criadas as famosas tabelas de histórico. Geralmente são utilizadas triggers do próprio BD para realizar essa tarefa. Esse padrão leva o nome de Log Trigger.
Nossa tabela historico_produto teria a seguinte estrutura
CREATE TABLE `historico_produto` (
id INT(6),
nome VARCHAR(30) NOT NULL,
preco DECIMAL(15,2) NOT NULL,
quantidade INT NOT NULL,
data_inicio DATETIME,
data_fim DATETIME
);
e essas seriam nossas triggers:
/* Trigger para INSERT */
CREATE TRIGGER HistoricoProdutoInsert AFTER INSERT ON produto FOR EACH ROW BEGIN
INSERT INTO historico_produto (id, nome, preco, quantidade, data_inicio, data_fim)
VALUES (New.id, New.nome, New.preco, New.quantidade, now(), NULL);
END;
/* Trigger para UPDATE */
CREATE TRIGGER HistoricoProdutoUpdate AFTER UPDATE ON produto FOR EACH ROW BEGIN
UPDATE historico_produto
SET data_fim = now()
WHERE id = OLD.id
AND data_fim IS NULL;
INSERT INTO historico_produto (id, nome, preco, quantidade, data_inicio, data_fim)
VALUES (New.id, New.nome, New.preco, New.quantidade, now(), NULL);
END;
Agora vamos refazer as operações e observar como ficaria a tabela de histórico:
INSERT INTO produto (nome, preco, quantidade, data_atualizacao) VALUES ('Amigurumi do Batman', 79.99, 30, now());
O insert acima acionará a trigger HistoricoProdutoInsert:
| id | nome | preco | quantidade | data_inicio | data_fim |
|---|---|---|---|---|---|
| 1 | Amigurumi do Batman | 79.99 | 30 | 2019-06-01 19:27:00 | NULL |
Agora vamos fazer o update no preço (trigger HistoricoProdutoUpdate)
UPDATE produto SET preco = 59.99 WHERE id = 1;
| id | nome | preco | quantidade | data_inicio | data_fim |
|---|---|---|---|---|---|
| 1 | Amigurumi do Batman | 79.99 | 30 | 2019-06-01 19:27:00 | 2019-06-02 19:27:00 |
| 1 | Amigurumi do Batman | 59.99 | 30 | 2019-06-02 19:27:00 | NULL |
Podemos ver que a trigger atualizou a coluna data_fim do registro anterior e adicionou um novo registro com as atualizações. Dessa forma, temos todos os dados de alterações que ocorreram no produto e, com algumas queries, podemos responder nossas perguntas. Sempre que quisermos o último snapshot do produto, podemos fazer a query WHERE data_fim = NULL, ou usar a combinação das duas colunas (data_inicio e data_fim) para obter o estado do produto em um determinado dia/horário.
Essa abordagem é bem simples e pode funcionar para muitos casos, mas ela possui um grande problema: todas as mudanças ficam visíveis apenas no nível do banco de dados, ou seja, a única interação possível com a tabela historico_produto é utilizando queries SQL. É praticamente impossível um sistema externo reagir à uma mudança no produto. (seria possível apenas fazendo pooling na tabela, mas convenhamos: não é uma boa ideia né?)
Como podemos fazer para capturar mudança nos dados e também permitir que sistemas externos reajam à eles? Simples: eventos!
Eventos representam ações que ocorreram em um determinado momento e permite, de forma assíncrona, que outros sistemas (internos ou externos) reajam à ele. Geralmente esses eventos trafegam em um sistema de mensageria, tais como: Kafka, RabbitMQ, VerneMQ, Amazon Kinesis…
Os eventos podem trafegar em diversos formatos (JSON, Avro, Parquet…), mas para facilitar a visualização, vamos usar JSON. Um exemplo de evento para o update do produto poderia ser
{
"id": 1,
"nome": "Amigurumi do Batman",
"preco": 59.99,
"quantidade": 30,
"data_atualizacao": "2019-06-01 15:30:00",
"operacao": "update"
}
e o código para enviar o evento seria parecido com esse:
public class RepositorioProduto {
private Evento evento;
public void atualiza(final Produto produto) {
// Salva produto no banco de dados
//Cria evento
Map<String, Object> dadosDoEvento = new HashMap<>();
dadosDoEvento.put("id", produto.getId());
dadosDoEvento.put("nome", produto.getNome());
dadosDoEvento.put("preco", produto.getPreco());
dadosDoEvento.put("quantidade", produto.getQuantidade());
dadosDoEvento.put("data_atualizacao", produto.getDataAtualizacao());
dadosDoEvento.put("operacao", "update");
//Envia o evento para o sistema de mensageria
evento.envia("ProdutoAtualizado", dadosDoEvento);
}
}
Dessa forma conseguimos publicar os eventos com as alterações para quem deseja escutá-los. O evento de ProdutoAtualizado por exemplo, poderia ser utilizado para enviar email marketing avisando os clientes que o preço do produto abaixou.
Essa abordagem resolve o problema das triggers, possibilitando outros sistemas reagirem às mudanças nos dados. Mas ela acarreta em outros problemas:
- Necessita de um grande conhecimento sobre o sistema que irá emitir os eventos, sabendo exatamente onde dispará-los, caso contrário, poderá haver divergências com o banco de dados
- Os famosos “updates na mão”, que não passam pelo sistema e consequentemente, não irá produzir os eventos necessários
- Arquitetura mais complexa do que as triggers, pois é necessário um sistema de mensageria
O cenário acima poderia ser evitado se o sistema em questão fosse desenvolvido usando técncias de Event Driven. Nesse tipo de abordagem, os eventos são considerados cidadãos de primeira classe, ou seja, toda a comunicação é realizada utilizando produtores e consumidores de eventos. Não me aprofundarei mais nesse assunto, pois quero escrever um post só sobre isso no futuro.
Vimos que tanto a abordagem por triggers quanto a por eventos tem suas limitações (o que é perfeitamente normal, afinal, não existe bala de prata). Mas e se pudéssemos fazer um mix das duas abordagem: pegar a consistência do banco de dados com a mensageria dos eventos? É exatamente isso que os frameworks atuais de CDC fazem. Antes de explicá-los, precisamos entender como funciona a replicação de banco de dados, ou mais especificamente, o binary log (aka binlog).
Irei explicar como funciona a replicação do MySQL, mas a maioria dos bancos RDBMS seguem o mesmo princípio. Veja a imagem abaixo:
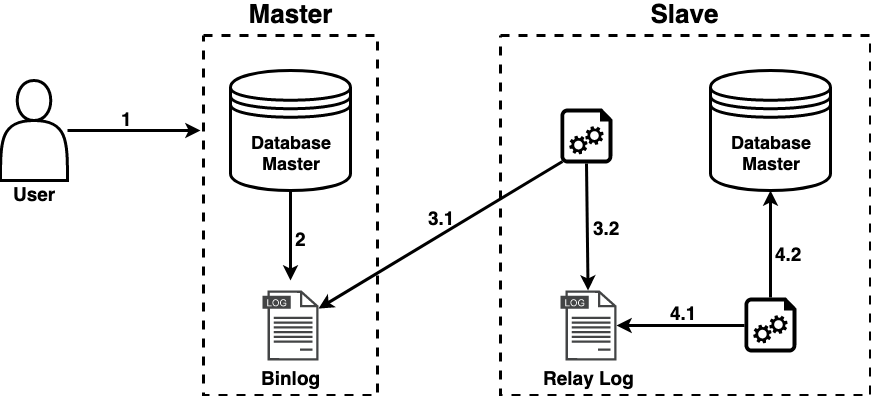
1 - A Master recebe o comando SQL
2 - Após executar o comando, a Master escreve no binlog as alterações feitas
3 - A Slave possui um processo que lê o binlog da Master (3.1) e escreve as alterações em seu relay_log (possui o mesmo formato do binlog) (3.2)
4 - A Slave possui outro processo que lê o relay_log (4.1) e aplica as alterações em seu host (4.2)
(mais detalhes na documentação oficial)
Olhando a imagem acima, podemos afirmar que todas as alterações feitas no banco de dados são escritas no binlog. E se conseguíssemos ler esses dados e mandar para um sistema de mensageria? É exatamente isso que o Debezium faz. Atualmente o Debezium é o framework open source mais utilizado para essa finalidade, suportando os seguintes bancos de dados:
- MySQL
- MongoDB
- PostgreSQL
- Oracle
- SQL Server
Incrementando o fluxo mostrado acima com o Debezium, teríamos uma arquitetura parecida com essa:
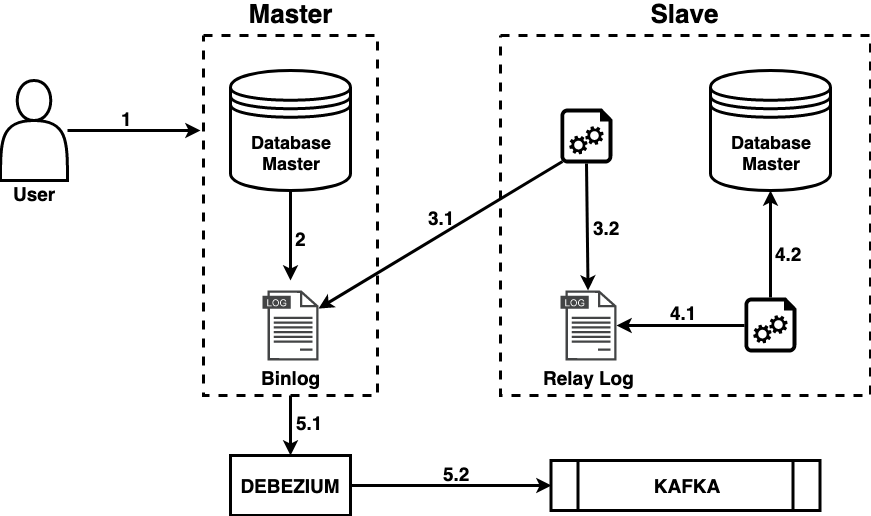
5 - O Debezium lê o binlog do banco de origem (5.1) e produz um evento no Kafka (5.2) representando aquela alteração.
Usando o CDC para obter os eventos diretamente do banco de dados, conseguimos o benefício da consistência dos dados com a facilidade de mensageria por eventos, habilitando assim, sistemas externos reagirem às ações que ocorreram, sem perder a consistência e com baixo acoplamento. Se fizemos uma associação entre as operações SQL na tabela produto e os eventos, podemos definir a seguinte regra:
| Operação SQL | Evento |
|---|---|
| INSERT | ProdutoCriado |
| UPDATE | ProductoAtualizado |
| DELETE | ProdutoRemovido |
| SELECT | Nenhum, pois não altera o estado do registro |
Dessa forma, podemos obter todos os eventos de um sistema com uma única implementação, olhando somente para o banco de dados. Além disso, os updates manuais não são um problema. Mas como dito acima, toda arquitetura possui limitações, e com o CDC não seria diferente:
- os eventos terão apenas dados da tabela, ou seja, perdemos quaisquer dados extra, como por exemplo: dados do request, sessão do usuário…
- para obter todos os detalhes das alterações, é necessário habilitar o nível mais agressivo de binlog
- se o banco de dados estiver mal modelado, será difícil consumir os eventos
- apenas o Kafka é suportado como sistema de mensageria no Debezium
No próximo post iremos mostrar na prática como funciona o Debezium com MySQL e Kafka.
Outros posts dessa série
- CDC parte 1 - Introdução ao Change Data Capture (CDC) (você está aqui)
- CDC parte 2 - CDC na prática com Debezium + MySQL (irei abordar de forma prática como utilizar o Debezium para obter eventos do MySQL)
- CDC parte 3 - Como usamos o CDC no Elo7 (mostrarei como utilizamos o CDC no Elo7, dos problemas que queremos resolver até a arquitetura final da solução)