Microserviços e REST (sério?)
Publicado em:
@ljtfreitas
@newton-beck
No trabalho da Engenharia do Elo7, temos múltiplas equipes dedicadas à nossa principal aplicação (o site do Elo7), segmentadas em diferentes domínios do negócio (carrinho de compras, pagamentos, integrações com Correios, etc). Também temos equipes focadas no uso de tecnologias específicas, como front-end, ferramentas de busca e plataformas mobile. O trabalho desenvolvido por todas essas equipes é inter-relacionado, sendo comum que diferentes aplicações, de diferentes times, precisem conversar entre si. Isso não é novidade, e existem muitas maneiras diferentes para implementar esse tipo de integração entre sistemas. Neste post, vamos falar um pouco sobre algumas possíveis estratégias, no contexto de microserviços, e diferentes abordagens de implementação.
Com sorte, esperamos poder ajudar você a encontrar possíveis caminhos para a sua aplicação e o seu contexto em particular.
Mas o que raios é um “microserviço”?
“O que é, por conseguinte, o tempo? Se ninguém me perguntar, eu sei; se o quiser explicar a quem me fizer a pergunta, já não o sei.” (Santo Agostinho, “Confissões”)
Atualmente, o modelo de sistemas distribuídos em destaque é a arquitetura baseada em microserviços. Mas por quê? O que é um microserviço? Onde vivem, o que comem? É interessante notar que, apesar da grande adoção na indústria e (muitas) discussões a respeito, ainda encontramos diversas explicações para o termo “microserviço”. Não temos a pretensão de escrever uma definição canônica sobre essa palavra, mas existe um certo consenso sobre o que os tais “microserviços” têm em comum.
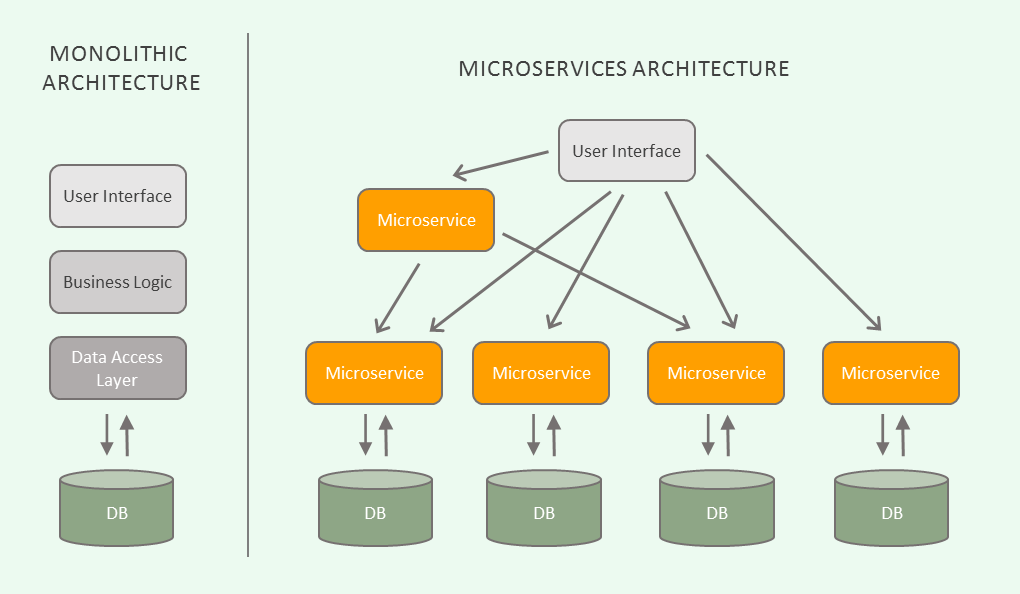
Podemos estabelecer uma comparação dos microserviços com uma arquitetura monolítica: um “monolito” é feito como uma única unidade, e todos os componentes da aplicação estão juntos no mesmo lugar. Ou seja, todo o conjunto de funcionalidades disponíveis na aplicação estão representados por uma única unidade lógica executável. Essa é a maneira mais natural, mais simples, mais prática e mais rápida de construir um sistema. Não obstante, conforme o software evolui, as coisas começam a ficar complicadas: se houver um problema na funcionalidade A que, digamos, seja grave o suficiente para derrubar a aplicação, a funcionalidade B, completamente diferente, também será comprometida. Ciclos de deploy começam a se tornar maiores e mais complexos, uma vez que pequenas mudanças ou correções isoladas precisam republicar a aplicação inteira. A escalabilidade também é comprometida, uma vez que não é possível escalar apenas funcionalidades que demandem mais recursos. E, além disso, a tendência é que a base de código se torne cada vez mais extensa, aumentando sua complexidade.
A arquitetura de microserviços propõe uma abordagem diferente: uma abordagem para desenvolver uma única aplicação como um conjunto de serviços, cada um sendo executado de maneira independente, em processos separados, se comunicando através de chamadas remotas. Sendo independentes, cada serviço terá o seu próprio processo de deploy e poderá escalar de acordo com suas necessidades em particular. Além disso, podem ser implementados com tecnologias diferentes uns dos outros e terem o seu próprio armazenamento de dados.
E quão “micro” o “microserviço” deve ser? Com o tempo, a experiência demonstrou que uma boa abordagem é segmentar serviços por contextos de negócio, de modo que cada um represente um requisito funcional da sua aplicação (no caso do Elo7, pagamentos, pedidos, produtos, etc). Podemos usar aqui o Princípio da Responsabilidade Única, mas aplicado à arquitetura: um microserviço deve fazer uma única coisa, e fazê-lo bem, usando as ferramentas adequadas ao contexto que o serviço representa.
Mas você já sabia de tudo isso, certo? Mais importante: o que a abordagem de microserviços tem de “novo”? Afinal, uma arquitetura baseada em componentes independentes é o pilar da idéia de sistemas distribuídos, e representar esses componentes como serviços é a idéia central do SOA.
Não é nosso objetivo fazer uma discussão sobre tudo o que envolve microserviços e a complexidade inerente a uma arquitetura distribuída (para uma explicação mais rica recomendamos este link). Para os fins do nosso artigo, vamos nos concentrar em um detalhe mais específico: a maneira como os serviços são expostos e como são consumidos.
Web services e API’s
“Que há em um nome? O que chamamos de rosa, com outro nome, exalaria o mesmo perfume tão agradável?” (William Shakespeare, “Romeu e Julieta”)
Yes, nós temos serviços. Como estabelecemos uma comunicação entre eles? Esta é uma preocupação importante, e que o monolito não possui: qualquer funcionalidade da aplicação pode ser consumida através de chamadas de método/função locais (em memória). Em uma arquitetura baseada em serviços, dado que cada um é executado em seu próprio processo, precisamos de chamadas remotas, e precisamos que os diferentes serviços sejam interoperáveis, de modo que o serviço A possa ser consumido sem dificuldades pelo serviço B. Como podemos conseguir isso?
Em arquiteturas basedas em SOA, frequentemente (mas não unicamente) esses serviços são conectados através de web services (o protocolo mais comum é o SOAP), eventualmente utilizando algum enterprise service bus ou ESB, e são mais frequentemente consumidos através de mecanismos de RPC (o acrônimo de “Remote Procedure Call”; essencialmente, consiste em representar uma chamada remota como uma chamada local de método, usando alguma estrutura fornecida pela linguagem em questão. No caso do Java, normalmente implementações geradas a partir do contrato de definição do serviço, ou proxy dinâmico de interfaces).
Existem muitas semelhanças entre o SOA e o modelo arquitetural dos microserviços, mas acreditamos que eles mais se diferem do que se parecem. Os conceitos de microserviços têm se afastado das idéias do SOA que descrevemos acima, especialmente no que se refere à coesão e tamanho dos serviços, e na maneira como as funcionalidades são expostas. Ao invés da orquestração via ESB, microserviços têm preferido a coreografia de múltiplas aplicações; ao invés de web services baseados em SOAP, microserviços têm preferido a exposição de API’s diretamente sobre HTTP.
A respeito da maneira como as funcionalidades do serviço são expostas, um detalhe que tem caracterizado os microserviços é a escolha do REST como estilo arquitetural. O conceito-chave do REST é a utilização do recurso como principal elemento de abstração do serviço. Sendo um modelo arquitetural, REST não é sobre protocolos, mas é mais comumente utilizado sobre o HTTP. Queremos nos concentrar nesse último detalhe em particular (a maneira como os serviços são expostos), que normalmente é reforçado como uma vantagem dos microserviços REST sobre os web services SOAP: expor uma API diretamente sobre HTTP é melhor?
Em nossa opinião, SIM, e é a opinião que a indústria de software têm adotado nos últimos anos. Mas é o suficiente? Se sim, qual formato de dados devemos utilizar? Utilizar JSON é o mais indicado para todas as situações? Estamos implementando corretamente o principal conceito do REST (a idéia do recurso)? Ou estamos apenas usando HTTP para expor URIs que trafegam JSON, e chamando isso de “API REST”?
REST e RPC
“As coisas valem pelas idéias que nos sugerem.” (Machado de Assis, “Trio em lá menor”)
Como dito antes, RPC é principalmente uma maneira de encapsular uma chamada remota em uma chamada de método/função local, ocultando a comunicação propriamente dita (para o cliente do serviço, equivale a utilizar um objeto que represente o serviço e utilizar seus métodos normalmente, enviando argumentos e capturando o retorno). Essa abordagem de consumo reflete um dos conceitos principais dos web services à la SOA, que consistem em, grosso modo, expor funcionalidades de negócio através de operações (“consultar”, “criar”, “excluir”, etc), que fazem sentido dentro do contexto de negócio de cada serviço em específico.
A abordagem do REST propõe que nos preocupemos com o que aquele serviço representa; as “operações” disponíveis já estão representadas pelos verbos da interface uniforme (o protocolo HTTP).
Essa é uma diferença fundamental, e a partir disto podemos (ousadamente) estabelecer que: REST é sobre substantivos (nomes); RPC é sobre verbos (ações).
Embora o termo “RPC” traga à lembrança protocolos pesados como SOAP e o uso de ferramentas SOA complexas, existem protocolos mais leves e muito utilizados como XML-RPC ou JSON-RPC. Na verdade, é muito mais comum encontrar uma API “RPC-like” do que utilizando as idéias do REST (não acredita? Continue lendo!).
Como exemplo, vamos imaginar um (micro)serviço que seja responsável pelo gerenciamento de um catálogo de produtos. Para listar todos os produtos, faremos uma requisição HTTP no formato abaixo:
GET /product/list HTTP/1.1
Host: api.example
Accept: application/json
E a resposta será uma coleção dos produtos disponíveis (no formato JSON). Digamos que a requisição abaixo crie um novo produto:
POST /product/create HTTP/1.1
Host: api.example
Content-Type: application/json
{name: "Product name"}
E a requisição abaixo altere os dados de um produto específico:
POST /product/update HTTP/1.1
Host: api.example
Content-Type: application/json
{id: 1234, name: "New Product name"}
Algumas implementações de API parecem crer que basta receber requisições diretamente através de HTTP para serem consideradas um serviço “REST”. Vejamos: os endpoints acima ("/product/list", “/product/create” e “/product/update”) estão em conformidade com o que o REST propõe? Em nossa opinião, a resposta é NÃO. E não estamos dizendo que é algo “ruim”; apenas que, tecnicamente, não é REST.
Nos exemplos acima, o formato das URLs não representam nenhum “recurso”. Estas URLs representam as operações disponíveis e expostas por esse serviço em termos de verbos: “list” , “create” e “update”. Esta é justamente a proposta das ferramentas de RPC, pois o uso de particularidades do protocolo (como o uso de verbos HTTP para representar diferentes ações) tem um papel secundário. Ok, estamos utilizando o verbo HTTP GET para obter os produtos, e POST para criar novos produtos; mas é um uso simplesmente acidental, pois utilizamos uma URL diferente para cada operação que desejamos realizar (alguns frameworks RPC utilizam os verbos HTTP adequados mas, novamente, é um uso meramente acidental, porque a semântica está representada pela operação exposta na URL). Algumas implementações, como o JSON-RPC, expõe uma única URL (por exemplo, “/product”) e o cliente deve enviar no corpo da requisição a operação a ser realizada (o que implica ao cliente enviar POSTs mesmo para obter dados, por exemplo).
Como podemos deixar nossos endpoints em maior conformidade com o que o REST propõe? Para retornar todos os produtos, poderíamos:
GET /product HTTP/1.1
Host: api.example
Accept: application/json
Aqui estamos usando o “product” como o substantivo, o que define o nosso serviço. O uso do verbo HTTP GET explicita que queremos retornar todos os produtos. Para criar um produto novo:
POST /product HTTP/1.1
Host: api.example
Content-Type: application/json
{name: "Product name"}
Novamente, “product” é o recurso; o uso do verbo POST explicita que desejamos criar um novo produto, que por sua vez será um novo recurso, disponível em outra URL (digamos, “/product/{identificador do produto}"). Se desejarmos alterar esse recurso, podemos utilizar o verbo PUT para demonstrar nossa intenção:
PUT /product/1234 HTTP/1.1
Host: api.example
Content-Type: application/json
{name: "New Product name"}
A abordagem REST é melhor? A partir dos exemplos acima, talvez você considere que sim, mas apenas porque, em nossa opinião, deliberadamente demonstramos um contexto no qual o uso do REST é mais apropriado do que a abordagem RPC. Mas será que sempre é o caso? Repassando o que declaramos no ínicio:
Sobre APIs REST:
- Uma API REST é modelada em termos de substantivos, modelando o domínio na forma de recursos; os verbos HTTP são utilizados para representar as operações disponíveis sobre esses recursos (verbos diferentes utilizados sobre o mesmo recurso representam diferentes operações).
- Eventualmente, pode ser complicado usar o restrito grupo de verbos HTTP para representar ações mais complexas; talvez você deva utilizar endpoints “RPC-like” (representando ações) para estes casos.
Sobre APIs RPC:
- Uma API RPC é modelada em termos de verbos, expondo funcionalidades como operações (ou chamadas de método/função).
- Eventualmente, a semântica do seu serviço pode ser prejudicada pelo fato das operações expostas representarem um conjunto de métodos, mas não um domínio; talvez você deva utilizar endpoints representando recursos ao invés de ações.
Dois casos de uso interessantes sobre essas abordagens são as APIs do Slack e do HipChat: ambas são ferramentas de comunicação em equipe, com suporte a salas privadas, conversas individuais, integrações externas, entre outras coisas. São contextos bastante parecidos. O Slack optou por criar uma API RPC; o HipChat, por uma abordagem REST. Será que alguma das duas é “melhor”? Provavelmente, não. O “melhor” é sempre a abordagem mais adequada para o problema que você quer resolver.
Frameworks REST e RPC
“Os homens em geral julgam mais pelos olhos do que pelas mãos, pois a todos é concedido ver, mas nem a todos é dado perceber.” (Nicolau Maquiavel, “O Príncipe”)
Expor um serviço REST é simples; há um grande número de frameworks web que tornam essa tarefa algo trivial. No Elo7, nossa principal linguagem é o Java, e para expor (micro)serviços normalmente utilizamos VRaptor e Spring MVC. Também temos serviços expostos em Scala, Ruby e Node. Em nossa opinião, é justamente essa facilidade que leva muitos desenvolvedores a verem o REST como o modelo “correto” (ou mesmo “o único modelo”) para integração de microserviços. Também podemos utilizar quaisquer desses frameworks para criar APIs “RPC-like” sobre HTTP facilmente. Mas existem frameworks especificamente para o modelo RPC?
Até aqui, discutimos o formato e semântica das URLs, mas utilizar um framework RPC é um passo além, e uma decisão que deve ser tomada cuidadosa e cautelosamente. Existem várias opções: gRPC, Apache Thrift, Finagle, entre outros. Talvez você ainda não conheça esses frameworks, mas são muito utilizados por empresas como Google, Twitter, Facebook, Pinterest, Foursquare, SoundCloud…(como pode perceber, empresas pequenas e desconhecidas :)).
Mas porque essas empresas não usam REST + JSON, como nos habituamos a fazer?
Em primeiro lugar, essas empresas utilizam esses frameworks em grande escala, mas somente para sistemas internos. Expor um serviço para clientes externos utilizando um framework RPC não é uma boa decisão; seus clientes (que você, potencialmente, não sabe quem são) serão forçados a utilizar a mesma tecnologia do serviço. E para sistemas internos? Uma vez que seus serviços estão inseridos dentro de um mesmo ecossistema (e não abertos ao mundo) talvez você possa vir a considerar que esta é uma limitação com a qual você possa conviver, dadas as vantagens (que relataremos também). Outro detalhe é a performance, uma vez que alguns destes frameworks RPC modernos foram especialmente projetados para suportar formatos binários (como serialização de objetos e protocol buffers) e outros protocolos além do HTTP.
Para o cliente/consumidor do serviço, o que muda? APIs REST, adequadamente orientadas a recurso, em nossa opinião, tendem a ser mais fáceis de entender, uma vez que o HTTP é utilizado como interface uniforme do serviço (tornando-o facilmente consumível a partir de qualquer linguagem/plataforma/framework/biblioteca que trabalhe com HTTP); o uso de URIs como identificadores de recursos, somado ao uso dos verbos HTTP, em nossa opinião, tende a melhorar a semântica dos serviços expostos (em nossa opinião, isso torna o uso da API mais “natural”).
No caso do RPC, é um pouco mais complicado. Se você estiver consumindo uma API “RPC-like” (como a do Slack, que citamos acima), isso vai exigir um pouco mais de documentação, uma vez que o cliente precisa conhecer exatamente cada operação disponível (que são diferentes URLs).
Mas se você optou por utilizar algum dos frameworks citados acima (ou mesmo outros, como Spring Remoting), o seu serviço será mais fácil de consumir a partir do código-fonte no cliente: bastará ter um “stub”, ou algum objeto/estrutura que represente o serviço exposto (no caso do Java, normalmente uma interface) e utilizar esse objeto normalmente, como chamadas de método normais. Frequentemente esse detalhe é citado como a maior vantagem da abordagem RPC: é muito fácil e transparente para o cliente consumir o serviço, uma vez que o mecanismo RPC de sua escolha irá encapsular e ocultar os detalhes de baixo nível da comunicação propriamente dita.
O detalhe de implementação perigoso em qualquer mecanismo de RPC é o acoplamento da tecnologia: dependendo do que você escolher utilizar, o cliente e o servidor deverão utilizar a mesma linguagem/framework. A evolução dos frameworks RPC modernos, nos anos recentes, reduziu significativamente essa limitação: o gRPC e o Thrift são compatíveis com várias linguagens (o servidor e o cliente podem ser implementados em linguagens diferentes), e o Finagle é compatível com qualquer linguagem que rode na JVM.
Outra diferença importante, da perspectiva do cliente, é o tratamento da resposta: em serviços REST o código de status da resposta é um detalhe que deve ser usado muito conscientemente, pois cada código possui uma semântica particular. Mesmo retornos de “sucesso” podem ter significados diferentes, como “Ok”, “Created” ou “Accepted”; isso confere ao cliente uma especial flexibilidade para implementar lógicas de granularidade fina, para casos específicos (como, por exemplo, uso do cache (código 304)). O mesmo ocorre em casos de erro (no HTTP, respostas de “erro” são representadas pelos códigos de resposta 4xx (Not Found, Bad Request, Unauthorized, etc) e 5xx (Bad Gateway, Internal Server Error, etc)). Além do código de status, a resposta também pode conter cabeçalhos indicando determinas situações (por exemplo, o cabeçalho “ETag”, usado para controle de concorrência). Em frameworks RPC, uma vez que os detalhes da comunicação HTTP são encapsulados, irá depender da implementação o nível de detalhes da resposta que você poderá acessar (normalmente o tratamento de erros do protocolo é realizado pelo próprio framework, que fornece para o cliente alguma estrutura de dados/objeto com os detalhes do problema).
Conclusão
“O que mais receamos é o que nos faz sair dos nossos hábitos.” (Fiódor Dostoiévski, “Crime e Castigo”)
Há uma grande quantidade de artigos disponíveis sobre as diferenças entre as abordagens REST e RPC, ao melhor estilo “este contra aquele”. Nosso maior objetivo com este post foi tentar demonstrar que esta é uma falsa dicotomia. Não escrevemos “REST vs RPC”, e sim “REST e RPC”. Não achamos que estas duas abordagens são mutuamente excludentes.
Não obstante, muitas APIs parecem adotar REST sem entender muito bem o porquê, e o resultado são serviços que soam estranhos às idéias do REST. Sim, nós adoramos REST + JSON, mas essa não é a única maneira de expor um serviço. Eventualmente, não será nem mesmo a abordagem mais adequada. Por outro lado, embora os frameworks RPC tenham ganhado muito espaço na discussão sobre microserviços (como citamos acima, algumas empresas de grande porte, com sistemas gigantescos, dão preferência a esses frameworks), muitas vezes trazem consigo uma carga de complexidade que pode ir além do que seu software precisa.
Em posts futuros discutiremos sobre como trabalhamos com monolitos, (micro)serviços, REST e RPC na Engenharia do Elo7.
Apesar do post longo e o tema complicado, agradecemos por ter lido até o fim :). E qualquer dúvida, comentário, ou crítica, esteja à vontade para utilizar a caixa de comentários!