
Desmistificando o Encoding
Publicado em:
@mariofts
Já reparou como é difícil fazer acentos, emojis e outros caracteres estranhos serem exibidos corretamente nos seus programas? Vamos entender um pouco sobre como funciona o armazenamento de caracteres e como fazer software que suporte múltiplas línguas da maneira correta. Sim, é muito mais que termos vários arquivos com as mensagens traduzidas…
Encoding é o mecanismo que define como representamos diversos símbolos e letras de diferentes alfabetos de maneira binária. Não tem nada a ver com idiomas, só com os símbolos. O mesmo caractere á pode ser representado de diversas maneiras, com 1, 2 ou mais bytes, dependendo do encoding usado. Mas por que isso é assim?
Um pouco de história
No início, havia o ASCII, uma tabela de 7 bits que representava “todos” os 128 caracteres “necessários”, e ainda sobrava 1 bit de espaço. Claro, isso falando da lingua inglesa, que não possui acentos, por exemplo. Quando os computadores começaram a se tornar populares em terras não dominadas pela Rainha ou pelo Tio Sam, esses 128 símbolos não eram suficientes para todas as letras de outros alfabetos, como grego, árabe, chinês, etc. Mas como havia um bit sobrando, cada país/fabricante de computador acabou criando seu própio mapa de caracteres usando o espaço restante, o que resultou em vários code pages. Apesar de solucionar parcialmente o problema (idiomas como o chinês que possuem muito mais de 256 caracteres/símbolos continuaram não suportados), ainda era muito difícil usar caracteres de dois code pages diferentes no mesmo arquivo (por exemplo, uma letra grega ∑ e o caracter de ¡ do espanhol).
O Unicode
Para organizar essa bagunça, surgiu o Unicode, uma espécie de mapa que inclui todos os caracteres de qualquer sistema de escrita usado em todas as línguas, e que ainda pode ser extendido para novos símbolos conforme estes forem surgindo. Um dos pontos mais importantes a se entender quando estamos falando de encoding é que o Unicode não é um encoding, já que ele não indica a forma binária de representação dos símbolos. O Unicode é um mapa do caractere para um code point, uma representação no formato U+0000. Por exemplo, o caractere á é o code point U+00E1, já o ç é o U+00E7. Repare que os codepoints estão em base hexadecimal, e podem ter quantos números forem necessários, como em U+1F60E, que representa o emoji 😎 .
Encodings
De volta aos encodings, existem diversas maneiras de armazenar esses caracteres em disco/memória. Como exemplo, usaremos a palavra olá. Vejamos como ela fica convertida para Unicode:
# Olá
U+006F U+006C U+00E1
A forma binária varia de encoding para encoding. Começaremos com um bem familiar, o ISO-8859-1, também conhecido como Latin1:
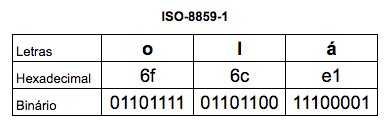
Olhando na tabela de caracteres do ISO-8859-1 é possível ver que o byte e1 é o que representa o caractere á. Um ponto muito importante a se notar é que o ISO-8859-1 é um encoding de byte único, ou seja, cada caractere sempre ocupa 1 byte e, sendo assim, só consegue representar até 256 caracteres diferentes.
Agora, vamos mudar a forma de armazenar nosso texto, usando um outro encoding bem famoso, o UTF-8:
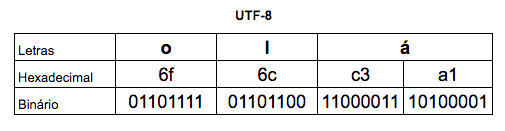
Veja que interessante, o mesmo texto que antes conseguia ser representado em 3 bytes, agora está ocupando 4 bytes de espaço, e para piorar, os últimos bytes nem são iguais! Antes de entrar em detalhes de como o UTF-8 funciona, podemos criar dois arquivos com o mesmo texto em encodings diferentes e consultar o tamanho deles no disco:

O arquivo em UTF-8 é maior que o em ISO-8859-1. Isso acontece porque o UTF-8 usa um esquema variável de bytes para representar cada caractere. Para os caracteres contidos na tabela ASCII, usa-se apenas 1 byte (127 bits somente); para caracteres diferentes, usa-se 2, 3, até 4 bytes para representá-los. Essa estrutura permite que o UTF-8 seja retrocompatível com antigos arquivos em ASCII, além de ocupar menos espaço quando o arquivo contém apenas os caracteres básicos da língua inglesa.
De onde vem os bebes problemas
Praticamente todos os problemas relacionados a encoding estão ligados a leitura de arquivos usando um encoding diferente do usado na escrita. Por exemplo, se tentarmos ler o arquivo ola-iso-8859-1.txt usando o encoding UTF-8, vejamos o que acontece:
# arquivo ola-iso-8859-1.txt aberto como UTF-8
ol�
Esse caractere � significa que algum byte do arquivo não possue caractere válido equivalente em UTF-8. Dependendo da fonte usada para exibição, pode ser que uma simples ? apareça no lugar também.
Outra possibilidade é tentar ler um arquivo UTF-8 usando o encoding ISO-8859-1:
# arquivo ola-utf-8.txt aberto como ISO-8859-1
olá
Aqui o problema é outro. Como o ISO-8859-1 só usa 1 byte para representar cada caractere, ao chegar na letra á, representada com 2 bytes pelo UTF-8, acabamos imprimindo dois caracteres, o à e o ¡.
Mas e na prática?
Em páginas web, além do encoding usado para salvar o arquivo, ainda temos que nos atentar ao cabeçalho <meta>, usado pelos navegadores para “adivinhar” qual o encoding da página. Sempre precisamos sincronizar o conteúdo desta tag com o encoding do arquivo html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<p>olá, este arquivo foi salvo como ISO-8859-1.</p>
</body>
</html>
A página acima é exibida no navegador com problemas:
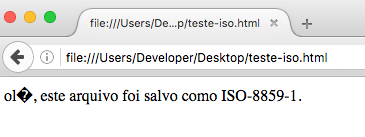
Para corrigir, devemos mudar o conteúdo da tag para o encoding correto:
<!DOCTYPE html>
<html>
<head>
<meta charset="ISO-8859-1">
</head>
<body>
<p>olá, este arquivo foi salvo como ISO-8859-1.</p>
</body>
</html>
A página agora é exibida corretamente:
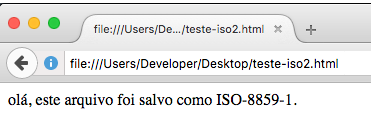
Conclusão
Além dos tópicos discutidos aqui, existem vários outros pontos onde problemas de encoding podem acontecer, como no banco de dados, por exemplo, (é possível customizar o encoding por database/tabela, e em alguns bancos até por coluna), ou ainda em arquivos .properties, que no Java por padrão sempre são escritos e lidos em ISO-8859-1. Resumindo, para evitar problemas com encoding, a melhor estratégia é sempre manter todos os seus arquivos/databases em UTF-8. É um encoding flexível, que não desperdiça espaço, e é o padrão em várias ferramentas, editores e linguagens de programação.